Comparison of NVIDIA A100, H100 + H200 GPUs
A significant player is pushing the boundaries and enabling data-intensive work like HPC and AI: NVIDIA!
This blog will briefly introduce and compare the A100, H100, and H200 GPUs. Consider it a short guide on which GPU should be preferred for which work. You will also be able to find important information, such as how many GPUs companies need for their Large Language Models (LLMs) as well as their energy consumption. Although Nvidia is the choice of many companies and researchers when developing and selling the technology, I will also touch on the supply-demand imbalance.
A100 — The Revolution in High-Performance Computing
The A100 is the pioneer of NVIDIA’s Ampere architecture and emerged as a GPU that redefined computing capability when it was introduced in the first half of 2020. The A100 has significantly improved, especially compared to its previous series, the Volta. These improvements have enabled it to quickly become the hardware of choice for researchers working on artificial intelligence (AI) projects, such as LLMs.
A100 has 6,912 CUDA cores, 432 tensor cores, and 40–80 GB of high bandwidth (HBM2). Third-generation Tensor Cores have accelerated AI tasks, leading to breakthroughs in image recognition, natural language processing, and speech recognition.
H100 — Performance and Optimization for Generative AI
The fourth-generation Tensor Core H100 of the Hopper architecture family introduced NVIDIA’s commitment to innovation.
The H100 is equipped with 18,432 CUDA cores, 640 Tensor Cores, 128 RT Cores, and 80 Streaming Multiprocessors (SMs), representing a new level in optimizing AI tasks. Thanks to NVLink interconnect technology, the H100 provides seamless and optimized integration from GPU to GPU. The H100 pioneered AI computing with its capability of machine learning and deep learning workloads. It offers single-precision performance up to 10.6 teraflops and dual-precision performance up to 5.3 teraflops.
While discussing H100, it is also essential to mention TensorRT-LLM. This open-source library was developed to improve and optimize the inference performance of the latest LLMs on the AI platform. It allows developers to try new LLMs without needing C++ or CUDA knowledge, enabling them to make high-performance and fast customizations.
Want to learn how to build modern software with LLMs using the newest tools and techniques in the field? Check out this free LLMOps course from industry expert Elvis Saravia of DAIR.AI!
H200 — Bet Up
NVIDIA is relentless in gaming and has continued this pace by introducing its latest gem, the H200, in November 2023. Developed based on Hopper architecture, the H200 stands out with its groundbreaking HBM3e memory. With a mind-blowing 141GB memory capacity at 4.8 terabytes per second, it will set a new standard for processing massive datasets in generative AI and High-Performance Computing (HPC) workloads. H200, which is planned to be available for sale in the second quarter of 2024, promises a performance increase exceeding the A100.
Comparison: A100 vs. H100 vs. H200
In the architecture race, the A100’s 80 GB HBM2 memory competes with the H100’s 80 GB HBM2 memory, while the H200’s revolutionary HBM3 draws attention.
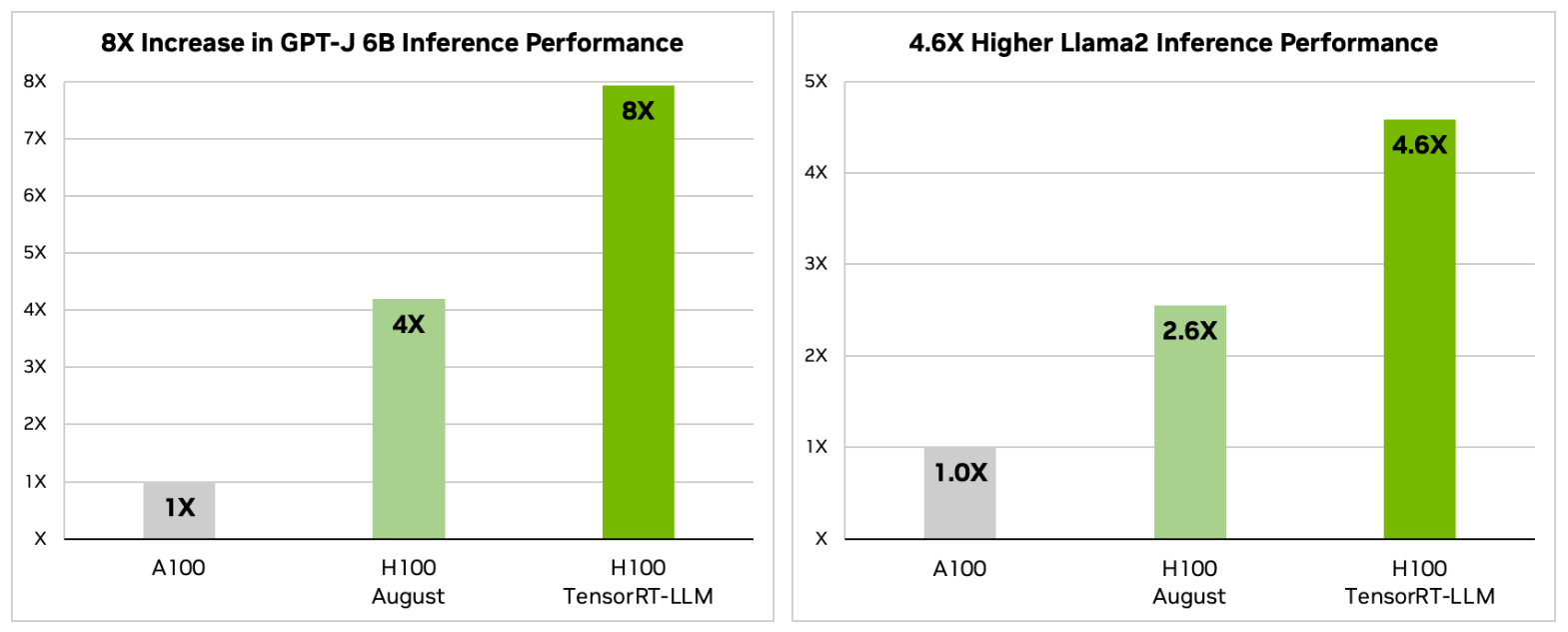
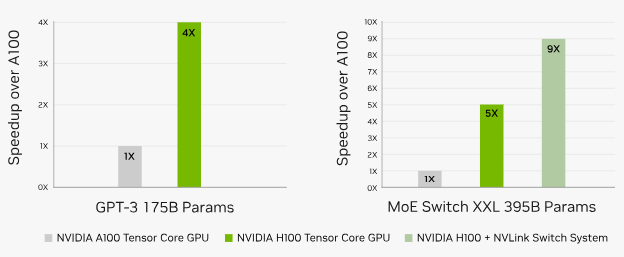
The inference performance comparison for GPT-J 6B and Llama2 70 B models shows that H100 is 4 times faster than A100. In particular, the H100 TensorRT-LLM version, which ensures optimal use of the hardware for LLM projects, exhibits 8 times higher inference performance than the A100. Although a performance difference is also observed for Meta’s Llama2 model, the performance increase rate between A100 and H100 decreases as the model parameters increase.
Power Efficiency: Fine Balances
Keeping Total Cost of Ownership (TCO) and energy consumption as low as possible is critical, especially for AI and LLM developers. Because these costs can be much greater than other costs, such as equipment, human resources, and connectivity needed for the rest of the project.
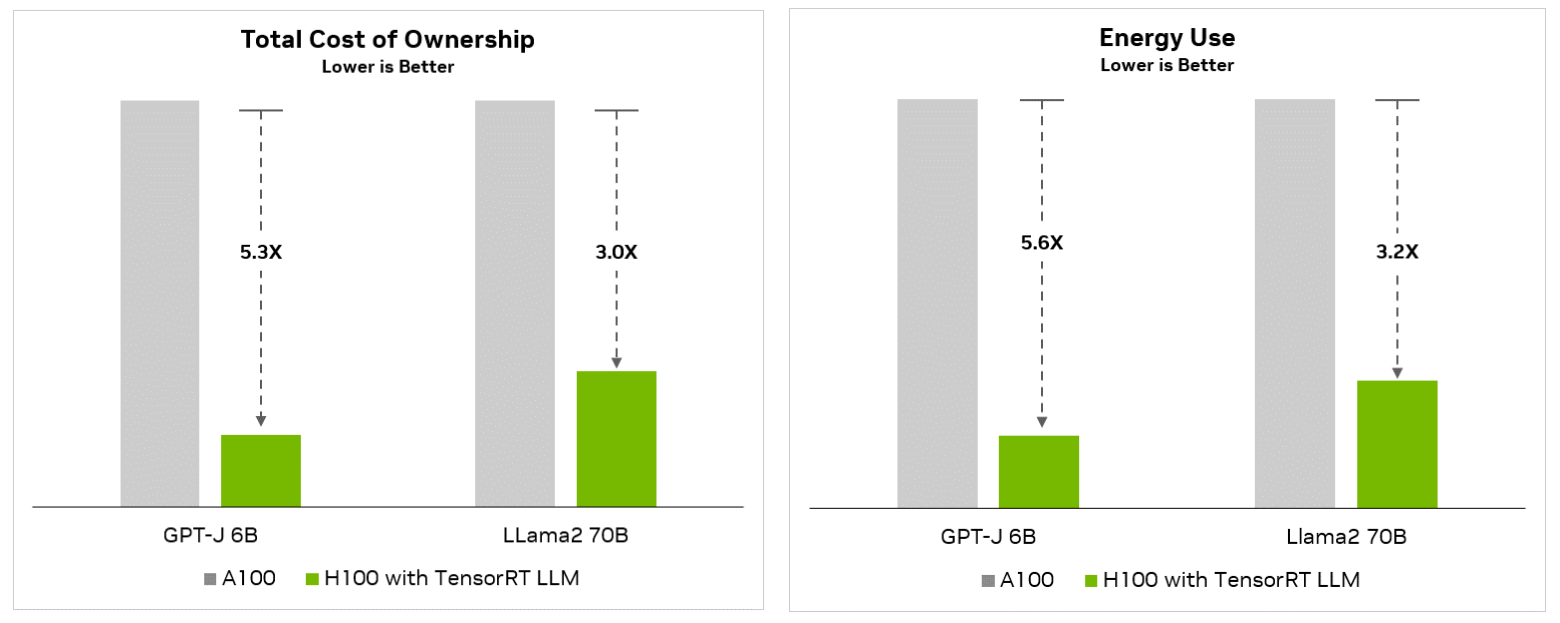
With its advanced architecture, H200 aims to establish a delicate balance between performance and power consumption and is expected to open new horizons for efficient AI computing. We will observe the developments on this issue over time.
Which One to Choose?
Choosing the proper GPU depends entirely on the need, and only some GPUs may be suitable for some scenarios. The A100 still delivers strong performance on intensive AI tasks and deep learning. A more budget-friendly option, the H100 can be preferred for graphics-intensive tasks. The H100’s optimizations, such as TensorRT-LLM and NVLink, show that it surpasses the A100, especially in the LLM area. The newly arrived H200 has an assertive position, especially in productive AI research and product development, with the expected performance increase and efficiency.
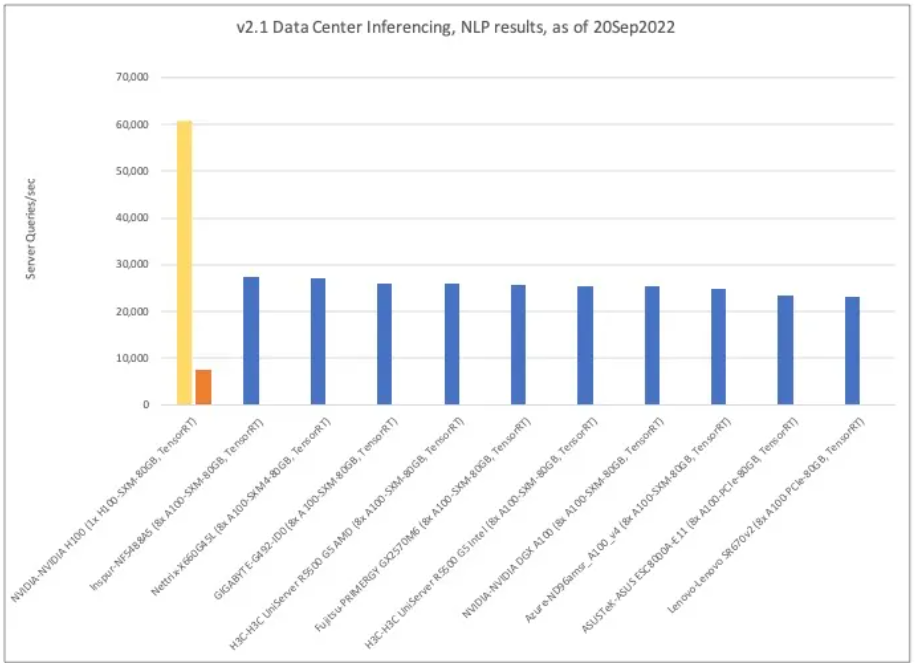
Below, 8 different A100 hardware configurations are compared for the same Natural Language Processing (NLP) inference. Although multiplying 1 H100 by 8 with linear scaling does not give the exact result, it appears to exceed the performance of other A100 experiments. This is similar to NVIDIA’s official posts. Having 8 H100s results in more than double the inference queries per second (~60,000 queries/sec) of the Netrix-X660G45L, achieving ~27,000 queries/sec in NLP compared to the Netrix-X660G45L (8x A100-SXM4–80GB, TensorRT). sec) is estimated to be possible.
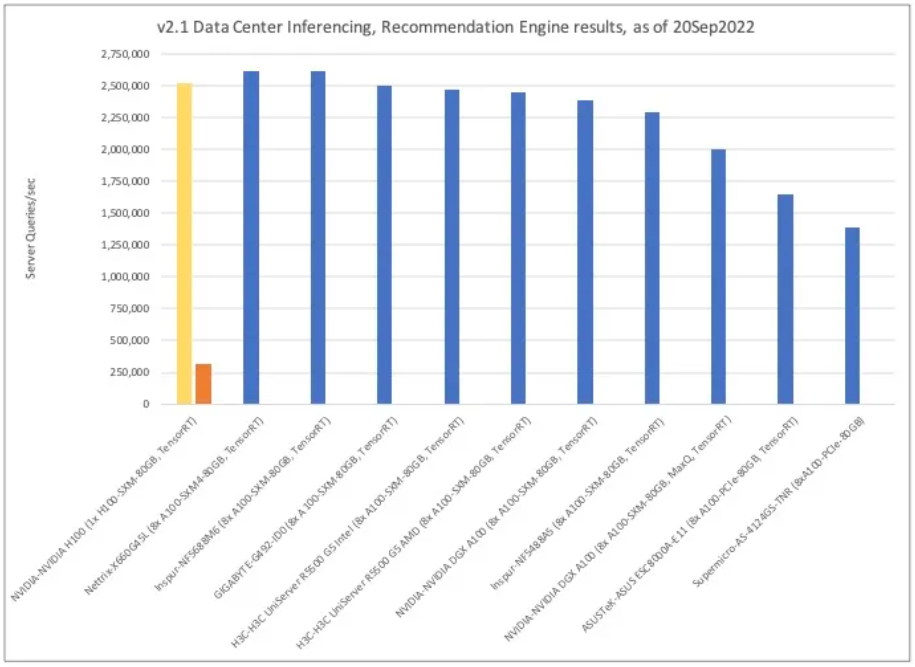
This time, instead of NLP, the (online) inference results per second for the recommendation engine application were compared similarly. It has been observed that having 8 H100s will perform 2.5 million recommendation engine inference queries per second while having 8 A100s is lower than the first two configurations. Both are estimated to perform 2.6 million inference queries per second. Solution #1 is the same Nettrix-X660G45L (8x A100-SXM(4)-80GB, TensorRT) and recommendation engine inference solution #2 is Inspur-NF5688M6 (8x A100-SXM(4)-80GB, TensorRT).
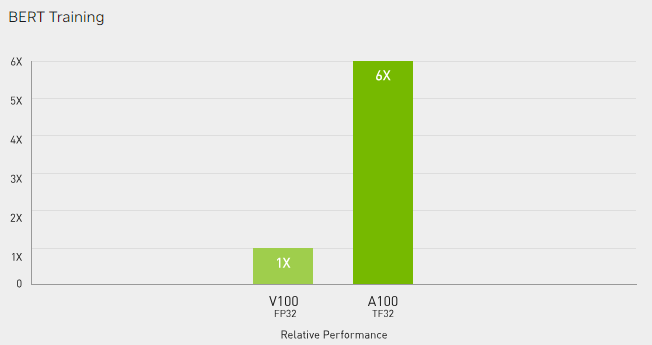
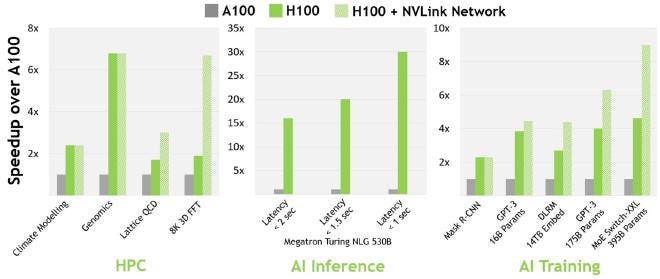
According to a comparison made by NVIDIA, For 16-bit inference, H100 is about 3.5 times faster, and for 16-bit training, H100 is about 2.3 times faster.
A100 Usage Scenarios
- Deep Learning and AI Training: With tensor cores and high computational performance, the A100 is well-suited for deep learning tasks, including training large neural networks for various applications such as image recognition, natural language processing, and more.
- AI Inference: A100 GPUs are used for AI inference workloads in which trained models are deployed to make real-time predictions or classifications. Tensor Cores contribute to efficient inference processing.
- HPC: A100 GPUs are used in HPC environments for complex scientific simulations, weather modeling, molecular dynamics simulations, and other computationally intensive tasks. High memory bandwidth and computing power are beneficial for such applications.
- Data analysis: A100 GPUs can accelerate data processing and analysis in scenarios where large data sets need to be processed quickly, such as data analytics and business intelligence.
- Cloud computing: A100 GPUs are integrated into cloud computing platforms, allowing users to access high-performance GPU resources for various workloads without needing on-premises hardware.
H100 Usage Scenarios
- LLMs: H100 is prominent in LLM and Gen-AI research, similar to A100.
- Numerical Simulations: Applications involving numerical simulations such as climate modeling, fluid dynamics, and finite element analysis can benefit from the H100’s HPC capabilities.
- Molecular Dynamics: Similar to A100, H100 can be used in molecular dynamics simulations to study the behavior of molecules and biological systems.
- HPC Clusters: H100 GPUs can be integrated into HPC clusters for parallel processing complex tasks across multiple nodes.
How Many Are Needed?
Similarly, the number of GPUs needed depends on the data type, size, and models used. As an example of how many of these GPU companies need, let’s look at the following examples for some major language models:
- For GPT-4, OpenAI probably trained the model with an A100 GPU around 10–25k.
- Meta has approximately 21k A100s, Tesla has around 7k, and Stability AI has about 5k.
- Falcon-40B was trained with 384 A100s.
- Inflection used 3.5k H100 for its GPT-3.5 equivalent model.
Supply-Demand Imbalance
Price and availability factors play a critical role in the GPU world. With their high performance, the A100 and H100 come at a higher cost, representing a significant investment for those who need raw power. Although the supply process for the A100 is generally faster, lead times of up to a year can sometimes be encountered for the H100. For start-ups who want to benefit from NVIDIA’s Inception program, it would be right to say that waiting is guaranteed, and prices continue to increase daily.
This problem also applies to companies such as OpenAI, and we sometimes see tweets shared by company executives about this issue.
“we are pausing new ChatGPT Plus sign-ups for a bit :(
the surge in usage post devday has exceeded our capacity and we want to make sure everyone has a great experience.” Sam Altman
Expected to be released in the second quarter of 2024, the H200 introduces a new player to the arena that promises advanced capabilities and efficiency.
Conclusion and Evaluation
In this article, I tried to briefly evaluate which model can be preferred in which situation to guide users in choosing a GPU. Additionally, emphasizing the number of GPUs companies need and the price/availability imbalance, we draw attention to the practical difficulties encountered in the hardware selection process.
- A100 and H100 are designed for different usage scenarios.
- A100 is designed more for HPC and AI tasks, while H100 suits graphics-intensive tasks. However, thanks to TensorRT-LLM, the H100 has radical performance improvement on LLM tasks.
- Healthcare, finance, climate, and natural language processing require specific hardware selection.
- The length of the supply process and the continuing price increase make it possible to carry out work by receiving services through cloud providers. However, legal obligations may prevent the use of the cloud for some projects and data.
References:
Related Articles


