Issue 13: ML for Creative User Interfaces and Experiences, Samples from Our AI Art Gallery
A new Comet Industry Q&A, a sampling of user submissions to our CLIPDraw public AI art gallery, and a few updates from around the ML industry
Welcome to issue #13 of The Comet Newsletter!
This week, we’re excited to share details about our next Industry Q&A exploring ML for creative UI/UX’s, as well as showcase some of our favorite pieces of AI-generated art from our recent CLIPDraw project (which you can read more about here).
Additionally, we jump back into the latest industry news—a 135 billion parameter model from Microsoft, why we might need a new theory of intelligence to achieve AGI, and two new datasets from Google for conversational NLP.
Like what you’re reading? Subscribe here.
And be sure to follow us on Twitter and LinkedIn — drop us a note if you have something we should cover in an upcoming issue!
Happy Reading,
Austin
Head of Community, Comet
FROM TEAM COMET | INDUSTRY | WHAT WE’RE READING | PROJECTS
Upcoming Industry Q&A: Building Creative User Interfaces and Experiences with Machine Learning

We’re really excited to share information about our next Industry Q&A, especially after how much we (and hopefully you!) enjoyed our July event on collaborative DS/ML—ICYMI, you can watch that full event + highlights on this YouTube playlist.
This month, we’ll be chatting with Hart Woolery of 2020CV and Victor Dibia of Cloudera Fast Forward Labs, two industry leaders at the forefront of building creative and immersive user interfaces and experiences that are powered by machine learning.
For more complete information, check out our full blog post preview. But here are the main details you need to know:
- Event theme: Building Creative User Interfaces and Experiences with Machine Learning
- Event date + time: Tuesday, August 24th, 1pm – 2pm ET (10am – 11am PT)
- Registration: You can register for this virtual event for free! We’ll also share links to the session and various highlights with those who register
We hope to see you at this and future events! And be sure to bring your questions for Hart and Victor, as we’ll save some time at the end for audience questions.
Save your seat
Samples from Comet’s AI art gallery, powered by CLIPDraw and Gradio
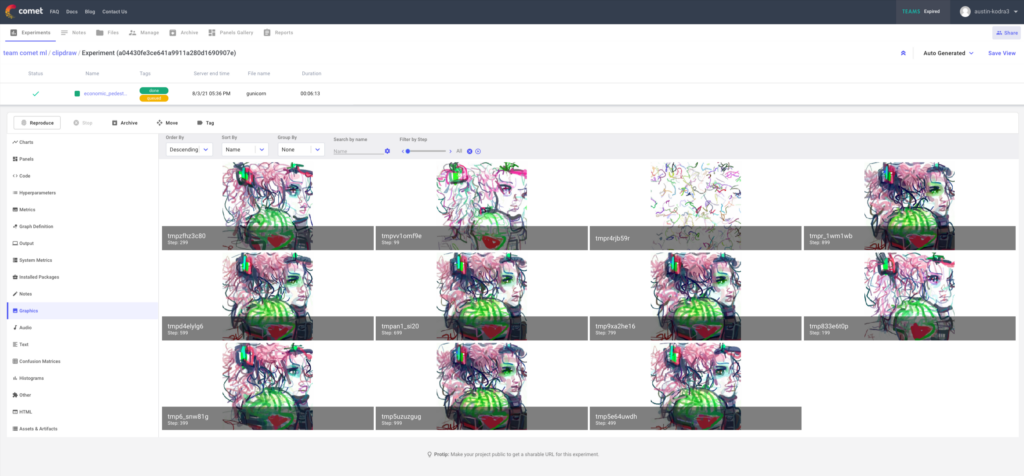
Last week, we shared a fun project that we hoped would allow us to build and showcase a community-generated art gallery by combining the powers of a generative art model (CLIPDraw), Gradio’s model testing UI, and Comet’s experiment management capabilities.
As of the writing of this newsletter, we’re up to more than 900 community submissions! So first, thank you for your support in turning this fun idea into a legitimate shared AI art project.
Second, we wanted to share a few of our favorite and most unique submissions from the bunch (see below and check out our thread on Twitter). If you’ve created something you like, let us know! Tag us on Twitter, reply to this email, or find me on LinkedIn—we’d love to share your creations with the community.
In case you missed this project last week, not to worry! Here are a few links to help you jump right in:
- Our Full Blog Post
- Project Interface
- Public Comet Project (with all submitted prompts)
- Colab Notebook Example




FROM TEAM COMET | INDUSTRY | WHAT WE’RE READING | PROJECTS | PERSPECTIVE
Microsoft AI researchers introduced a 135 billion-parameter neural net and deployed it on Bing to improve search results
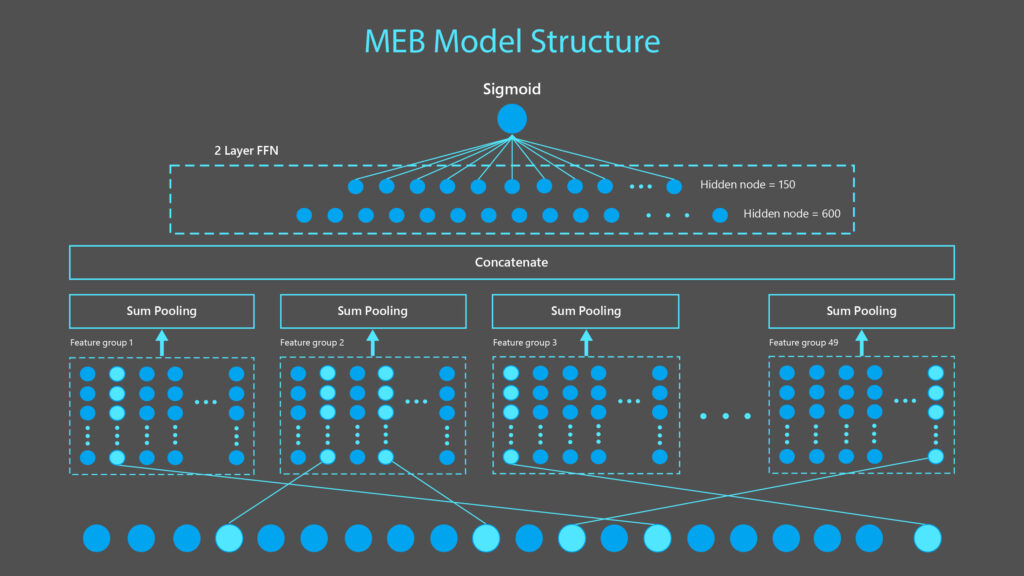
Microsoft is calling the project “MEB”, which stands for “Make Every Feature Binary”, and is designed with the intention of pushing language understanding beyond semantic relationships—an important part of helping search engines more effectively match queries with target documents and webpages.
At 135bn parameters, it’s not the biggest neural network we’ve seen (that honor goes to OpenAI’s famous GPT-3, at 175bn), but MEB does have a few unique properties that differentiate it from other large language models.
Specifically, MEB can map single features, meaning that it’s less likely to overgeneralize, and can take a fill-in-the-blank problem (i.e. “____ can fly”) and create a feature map that includes many possibilities, not just the one that might be the most obvious (“birds”).
The researchers at Microsoft behind this effort explain this process well, noting that “MEB…can assign weights that distinguish between the ability to fly in, say, a penguin and a puffin. It can do this for each of the characteristics that make a bird—or any entity or object for that matter—singular. Instead of saying “birds can fly,” MEB paired with Transformer models can take this to another level of classification, saying “birds can fly, except ostriches, penguins, and these other birds.”
According to the Microsoft team, Bing has also seen some tangible improvements from this effort, including a (nearly) 2% increase in clickthrough rate on top search results, and a more than 1% reduction in query reformulation (i.e. users having to reshape an original query because of unhelpful results).
Read Microsoft’s full blog post here
FROM TEAM COMET | INDUSTRY | WHAT WE’RE READING | PROJECTS | PERSPECTIVE
To create AGI, we need a new theory of intelligence

If you’ve ever watched or read general interest science fiction about AI, then you might know that the “holy grail” of the technology is AGI, or Artificial General Intelligence—the threshold at which computers can act and think like humans.
But the pursuit has served as an ongoing enigma for researchers and scientists. Ben Dickson, writing for VentureBeat, explores some of the barriers to AGI through the lens of new research on the “considered response theory,” from Sathyanaraya Raghavachary, Associate Professor of Computer Science at the University of Southern California.
Essentially, Raghavachary argues that life and levels of intelligence are composed of structures that consider and produce responses, “meant to [help] an agent survive and reproduce in its environment by interacting with it appropriately.”
This conception of intelligence is quite a bit different from the processes underlying most AI systems, and our assumptions about how machine intelligence works—mechanisms and principles like reason, planning, goal-seeking, and more.
Furthermore, biological intelligence is “embodied”, meaning there are direct and inextricable connections between “mind” and body” that today’s AI systems are unable to replicate.
Read the full report in VentureBeat.
FROM TEAM COMET | INDUSTRY | WHAT WE’RE READING | PROJECTS
Two New Datasets for Conversational NLP: TimeDial and Disfl-QA

Last week, Google introduced two new datasets for conversational AI systems: “TimeDial, for temporal commonsense reasoning in dialog, and Disfl-QA, which focuses on contextual disfluencies.”
Much like the problem Microsoft was looking to solve with MEB (see above), conversational agents struggle with fill-in-the-blank scenarios, especially when those blanks assume certain temporal inter-dependencies and reasoning that might seem obvious to humans. TimeDial consists of roughly 1,500 dialogues that are presented in multiple choice format with options that represent one temporal span. The model is then asked to select all “correct” answers among the 4 options.
Disfl-QA is aimed at solving issues that conversational agents have with disfluency (interruptions in regular speech flows, i.e. “When is Lent, I mean, Easter, this year?”), typically in speech recognition systems. Disfl-QA is the first dataset that’s targeted specifically at these kinds of speech irregularities, making it an incredibly important data source for training more performant speech recognition systems.
Related Articles