ML updates from Google I/O, a Python library that helps you calculate your code’s carbon footprint, and more
Welcome to issue #2 of The Comet Newsletter!
This week, we take a closer look at the wide range of interesting ML news coming out of Google I/O, and share a blog post from Twitter discussing why their team scrapped an image cropping model.
Additionally, you might enjoy a new Talk Python podcast episode exploring a Python library that you can use to track the carbon footprint of your code—as well as a tutorial showing you how to integrate the library with Comet.
Like what you’re reading? Subscribe here.
And be sure to follow us on Twitter and LinkedIn — drop us a note if you have something we should cover in an upcoming issue!
Happy Reading,
Austin
Head of Community, Comet
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
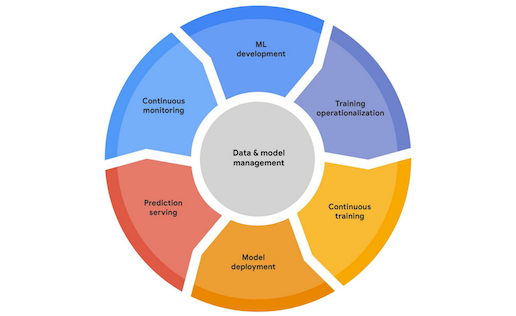
Google I/O 2021: Enhanced speech and image tech, ML privacy on Android, and the introduction of Vertex
This year’s Google I/O saw the company make big ML announcements—in Speech and Image technology, as well as in tooling for Machine Learning model development on cloud and mobile platforms.
The star of the show was LaMBDA (Language Model for Dialogue Applications), Google’s new conversation model. LaMBDA continues the trend of applying large transformer models to solve natural language problems. Unlike most other language models, LaMDA has been trained on dialogue data. The intent here is to find ways for the model to address the open ended-ness of real conversations.
“A chat with a friend about a TV show could evolve into a discussion about the country where the show was filmed before settling on a debate about that country’s best regional cuisine,” explained Eli Collins and Zoubin Ghahramani of Google. “That meandering quality can quickly stump modern conversational agents (commonly known as chatbots), which tend to follow narrow, pre-defined paths.”
In the computer vision space, the company has taken steps towards updating its camera and imaging technology to be more inclusive of skin tone. Historically, image processing tends to be tuned for lighter skin tones and not that of black and brown subjects. Google has taken steps to improve its auto-white balance and exposure algorithms to have better accuracy for dark skin tones based on a broader dataset of images featuring black and brown faces.
Google is also providing enhanced tooling and support for privacy-preserving ML for Android. Russell Brandom discussed these new capabilities in his write-up in The Verge: “Android’s new Private Compute Core will be a privileged space within the operating system, similar to the partitions used for passwords or sensitive biometric data. But instead of holding credentials, the computing core will hold data for use in machine learning, like the data used for the Smart Reply text message feature.”
Greater public scrutiny of how large tech companies collect and use customer data is the likely motivator behind this move. One may see this as a preemptive effort from Google to avoid legal altercations similar to the ongoing one between Apple and Facebook
Finally, Google announced their new Cloud ML Platform, Vertex AI. The goal of the platform is to provide a single UI and API for all of Google’s Cloud Services for building, training, and deploying machine learning models at scale.
There is on-going debate as to whether the MLOps market is best suited for end-to-end platforms or a best-of-breeds model. Machine Learning as a field moves very quickly, and it is difficult to encompass all the needs of a machine learning team into a single product that can be effectively maintained. Read more about this debate here.
Looking for more? Check out this full rundown of all the announcements from this year’s event.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
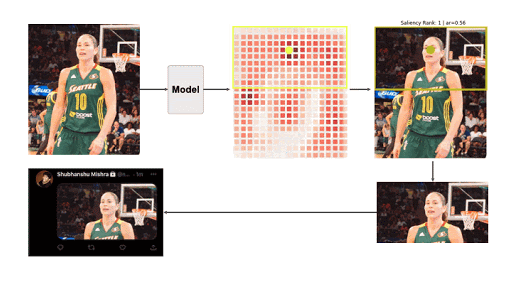
Twitter shares learning from their image cropping algorithm
In this retrospective, Dr. Rumman Chowdhury, a Director of Software Engineering at Twitter, explains the issues leading up to the decision to ditch their Image Cropping algorithm. In early 2018, Twitter started using ML to automate image cropping on it’s platform. In October of 2020, they started receiving complaints that the cropping did not serve all people equitably. Dr. Chowdhry’s team went through an extensive review of the algorithm, and put into place improvements for assessing algorithms for potential bias and for understanding whether ML is the best solution to the problem at hand. They uncovered three key areas where the model was failing, and eventually decided that the best solution was to include a cropping preview option within the product so that users had final say over how their images were presented.
“This really highlights the importance of thinking about the potential impact of ML models and why we build them in the first place. Sometimes, it is easier to just fix the root cause” – Jacques Verre, Product Manager @Comet
Read Dr. Chowdhury’s full retro here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION

CodeCarbon: Calculate and visualize your code’s C02 impact
Check out this excellent episode of the Talk Python podcast, where the team behind CodeCarbon—including our own Boris Feld—discusses the Python library, which lets you calculate and visualize your ML code’s carbon footprint. Given the huge compute costs associated with training state of the art machine learning models, it is imperative that the ML community embrace tools that allow us to better gauge the impact of our work on the environment.
You can also learn more about the open-source CodeCarbon library—and how to integrate it with Comet—in an excellent write up by Niko Laskaris.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION

Towards Human-Centered Explainable AI: the journey so far
In this post, Upol Ehsan questions the myth that “If you can just open the black box, everything else will be fine”. Ehsan talks about his experience building Explainable AI Systems, and the importance of understanding the “who” the human in the loop is when building such systems.
“Explainability is a human factor. It is a shared meaning-making process that occurs between explainer(s) and explainee(s).”
