Hugging Face provides awesome APIs for Natural Language Modeling. In particular, they make working with large transformer models incredibly easy. These models can be used off-the-shelf for text generation, translation, and question answering, as well as downstream tasks such as text classification. The API also allows for seamless interoperability between Tensorflow and Pytorch models. In this post we’re going to show you how to get started with auto-logging model metrics and parameters to Comet from the Hugging Face transformers library. All code for this post can be found in this Colab Notebook.
See the logged experiments in the Comet UI here.
Auto-Logging to Comet
To get started, you just need to have Comet installed and your Comet API key defined. You can find instructions to do that here. Comet integrates with Hugging Face’s Trainer/TFTrainer object, and automatically logs training metrics and parameters without requiring any changes to your source code. In order to enable logging to Comet, all we have to do is set the following environment variables.
export COMET_API_KEY="YOUR API KEY" export COMET_PROJECT_NAME="YOUR PROJECT NAME"
That’s it! Auto-logging the model metrics and parameters will work as long as you use either the Trainer or TFTrainer object to train your model. Feel free to try it by running the relevant examples provided in the Hugging Face repository.
Let’s look at some examples of what Comet is auto-logging. We’re going to train a model to assign conference labels to research papers based on the title of the paper. We will perform a simple grid search over the batch size, learning rate and weight decay parameters for different versions of the BERT model.
Consider the following snippet. For the sake of brevity, the data preparation steps have been omitted. You can find the full source code in this Colab Notebook. Logged experiments from the notebook can be found here.
import itertools
import torch
import transformers
from transformers import AutoTokenizer
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
from tqdm import tqdm
PRE_TRAINED_MODEL_NAME = "distilbert-base-uncased"
EPOCHS = 5
WEIGHT_DECAY = 0.99
model = BertForSequenceClassification.from_pretrained(
PRE_TRAINED_MODEL_NAME,
num_labels=2,
output_attentions=False,
output_hidden_states=False,
)
# Tell pytorch to run this model on the GPU.
model.cuda()
decays = [0.0, 0.5, 0.99]
learning_rates = [5.0e-5, 3.0e-5, 2.0e-5, 1.0e-5]
batch_sizes = [32, 64, 128]
parameters = [
{"weight_decay": x[0], "learning_rate": x[1], "batch_size": x[2]} for x in list(itertools.product(*[decays, learning_rates, batch_sizes]))
]
for idx, p in tqdm(enumerate(parameters)):
weight_decay = p["weight_decay"]
learning_rate = p["learning_rate"]
batch_size = p["batch_size"]
training_args = TrainingArguments(
seed=42,
output_dir='./results',
overwrite_output_dir=True,
num_train_epochs=EPOCHS,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_steps=500,
weight_decay=weight_decay,
learning_rate=learning_rate,
evaluation_strategy="epoch",
do_train=True,
do_eval=True
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Calling the train method will automatically create a Comet project to log your experiment results. If you pass a callback function to compute metrics on the validation dataset, Comet will automatically log the metrics that were defined in the callback, and append the appropriate context to the name. In our example, we are computing the loss, accuracy, and f1 score on the validation set. Logging to Comet happens in real time, so we can visualize how these metrics change over the course of training.
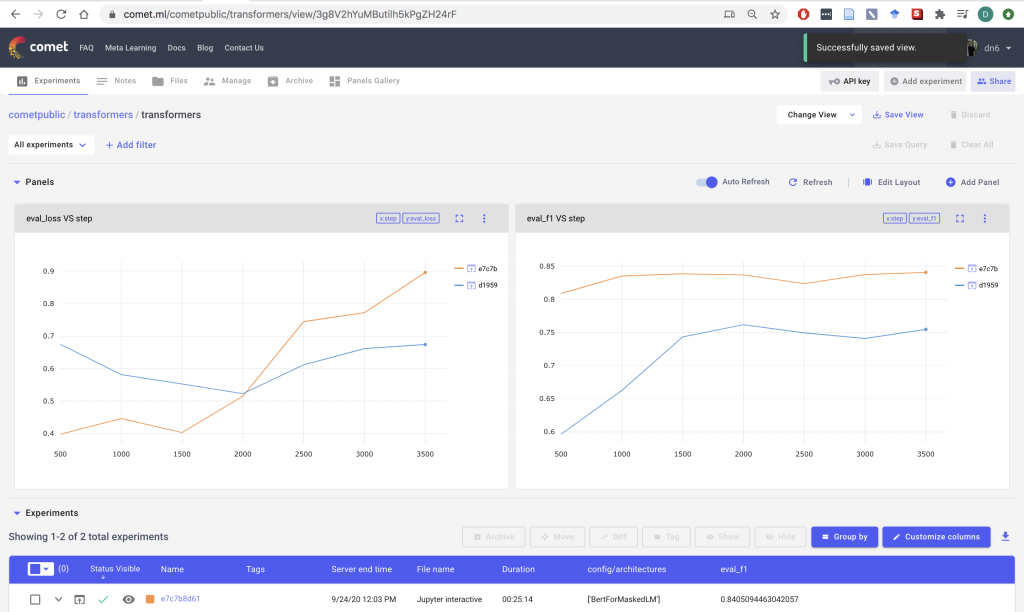
Figure 1. Plots for autologged metrics (link to experiment)
Comet will also automatically log all parameters defined in the TrainingArgs object, and allows searching for parameters of interest within the experiment.
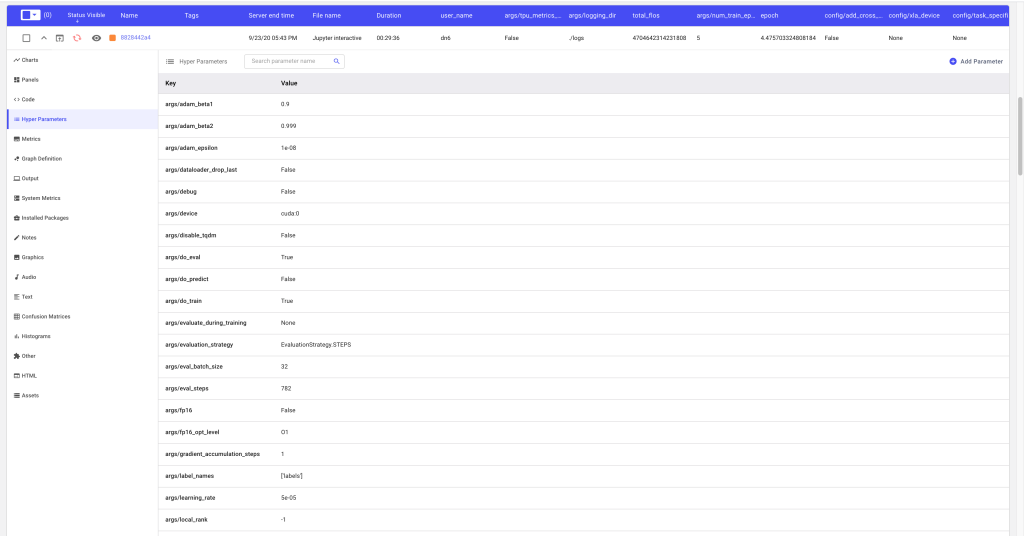
Figure 2. Logged Parameters from TrainingArgs (link to experiment)
We can log similar metrics for other versions of the BERT model by simply changing the PRE_TRAINED_MODEL_NAME in the code and rerunning the Colab Notebook. A full list of model names has been provided by Hugging Face here.
Comet makes it easy to compare the differences in parameters and metrics between the two models
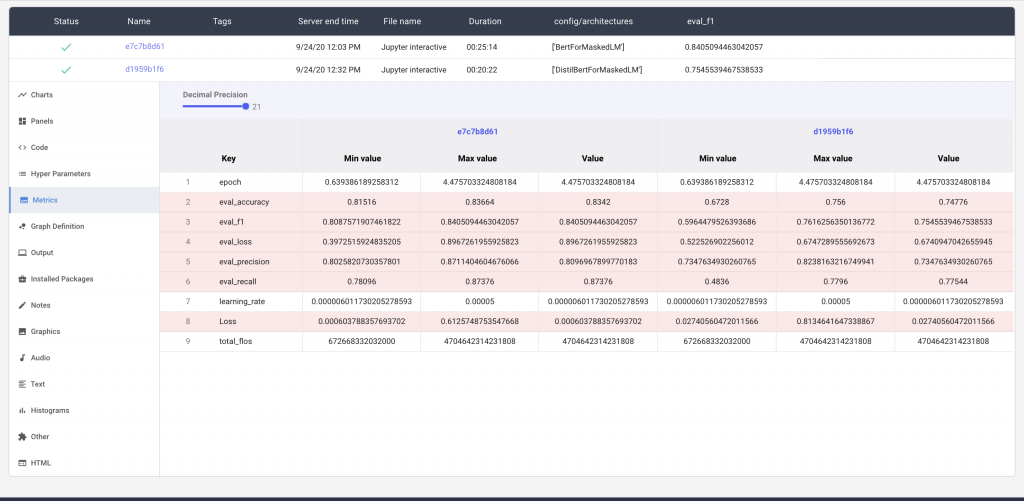
Figure 3. Differences between Two Models (link to experiment)
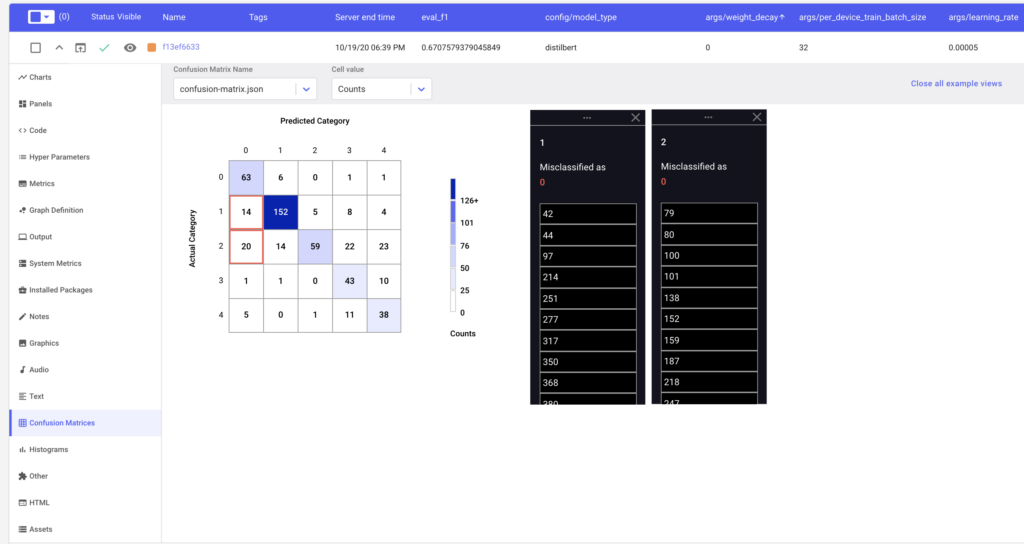
Additionally, we can log more advanced features such as Confusion Matrices, using the compute_metrics function.
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
experiment = comet_ml.config.get_global_experiment()
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
experiment.log_confusion_matrix(preds, labels)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}We can now visually inspect our precision and recall metrics, as well as view the misclassified examples.
Finally, we can compare the model performances across the different model parameters using a Parallel Coordinates chart.
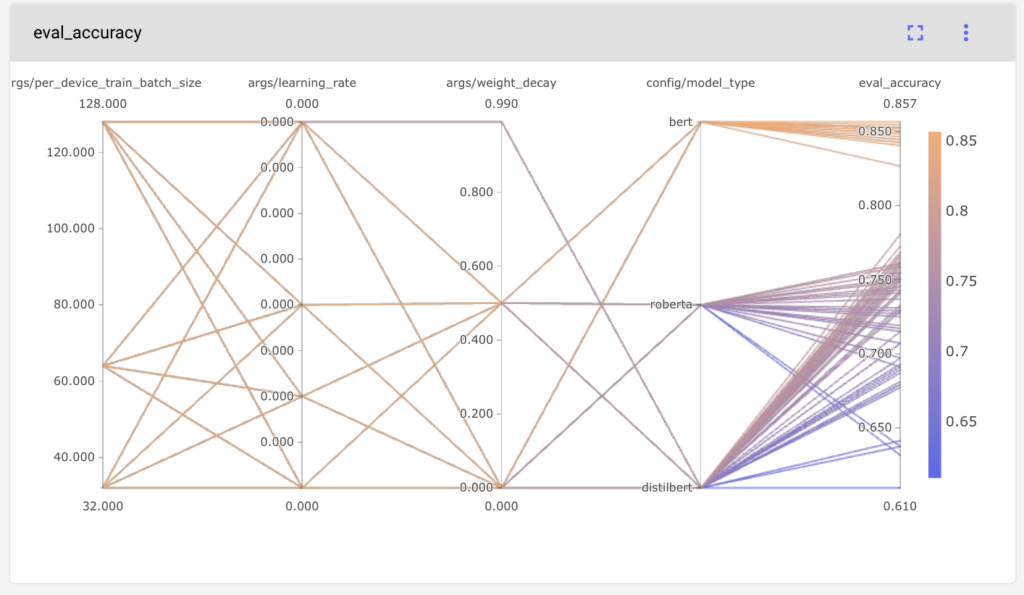
Figure 5. Parallel Coordinates Charts of Model Hyperparameters
Conclusion
Debugging transformer models has never been easier with Comet’s auto-logging integration for Hugging Face.
Have a look at the experiment results here and try out the Colab Notebook here.
Additionally, we provide finer controls for logging through other environment variables. You can control whether you want to log to the Web UI by either setting COMET_MODE to ONLINE or OFFLINE. You can also disable logging to Comet entirely by setting COMET_MODE to DISABLE.
A more comprehensive list of these environment variables is available here. There are several experiment parameters that can be configured through these variables and they can be set in a variety of ways.
We hope to see transformative things being built with Comet and Hugging Face!
