With the rise of neural network NLP models, many practitioners are wondering how to best configure a model to perform a particular task. For example, how should I structure a model to perform sentiment analysis? Translation? Essay generation?
In this post, I will discuss the three dominant model architectures used in NLP today, and when each should be used to maximize your model’s performance and efficiency.
Architectures
Encoder-Only
This type of model takes as input a sequence of words and produces a fixed number of outputs. For example, if I want to use an encoder only architecture to classify the sentiment of a sentence, I will always predict 1 number — either a 1 (for “positive”) or a 0 (for “negative”). The same goes for predicting movie star ratings — I will still predict 1 number, though it can be either 1, 2, 3, 4, or 5. If I were to do entity detection— i.e., tagging each word as being a “person”, “number”, “location”, etc., I could use an encoder-only model to predict the number of tokens equal to the length of the input sequence.
In general, if you know exactly how many numbers/words you want your NLP model to output, the encoder-only architecture is likely best. Unlike the next two configurations I will discuss, it neither needs to waste model space trying to figure out how many values need to be outputted nor restricts a model’s ability to look at all words in an input sequence to make a decision. Some examples of popular encoder-only NLP models are BERT (Devlin et al., 2018), RoBERTA (Liu et al., 2019), DeBERTa (He et al., 2020), and ELECTRA (Clark et al., 2020).
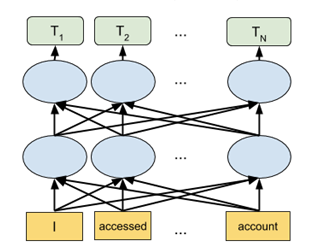
Decoder-Only
Like the encoder-only model, the decoder-only model setup also takes as input a sequence of words. However, it differs in that rather than trying to predict a fixed sequence of numbers or tokens, it attempts to actually output a text sequence. This is advantageous if your task’s output is variable — e.g., if you train a model to answer questions, the answers to “What is the capital of Germany?” and “What is the General Theory of Relativity?” will have very different lengths.
However, there is a cost to this output flexibility — while the encoder-only model gets to make decisions based on seeing every word in the input sequence, the decoder-only model only has partial visibility. In particular, a neuron corresponding to the nth word of the input sequence can only make decisions based on the previous n-1 words — it cannot look forward. This ends up significantly hurting its performance for a given model size.
Existing ML applications may surprise you — watch our interview with GE Healthcare’s Vignesh Shetty to learn how his team is using ML in the healthcare setting.
To provide an example, two of the best models of 2018 were decoder-only GPT (Radford et al., 2018) and encoder-only BERT (Devlin et al., 2018). Despite GPT being 36% larger (150 million parameters to 110 parameters), it actually performed 6% worse on a natural language understanding test called GLUE (75.1 vs 79.6). Some of the most famous decoder-only models are the GPT series made by OpenAI and EleutherAI. This type of model is best used for tasks like freestyle text generation and language modeling.

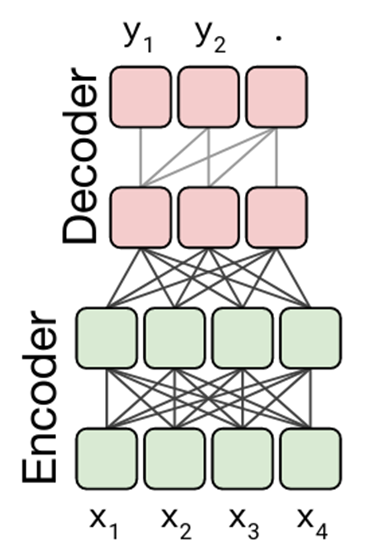
Encoder-Decoder Model
This type of model combines the encoder-only and decoder-only setups to try and get the best of both worlds. The model starts by taking an input sequence and passing it through an encoder. This encoder outputs what we call a context vector — a set of numbers of fixed size that basically represents the model’s understanding of the input (think of this as the state of your brain’s neurons as you are listening to someone’s request). The decoder then takes this context vector and uses it to output the result.
This setup ends up preserving the decoder’s ability to have variable length generations while reducing the inefficiencies associated with only having partial visibility of the sequence. This type of model works quite well for machine translation (e.g., translating from Language A to Language B, where a language could be a human language, a programming language, etc.), summarization, and question answering. Examples of models using this architecture include T5 (Raffel et al., 2019), BART (Liu et al., 2019), PEGASUS (Zhang et al., 2019), and Meena (Adiwardana et al., 2020).
Based on this analysis, it seems that decoder-only models are largely redundant. Why use one if you can get the benefit of variable-length outputs while minimizing performance losses with an encoder-decoder setup? The answer lies in situations where you don’t have a lot of data. Modern NLP models do a very good job of learning whatever task you put in front of them, but if you don’t have very much data, the model is only going to learn the bare minimum needed to master the task for that small dataset and will perform poorly everywhere else.
However, decoders that have been pre-trained on language modeling (that is, they were provided a large dataset and were tasked with predicting what words were most likely to come after the input sequence) can get around this by using a method called prompting.
To explain how prompting works, let’s take an example from our sentiment classification task. We want our model to take as input a sentence like “I was extremely ecstatic when I got my new dog.” and predict “1” for positive. We can use prompting to reformulate this task as taking as input: “I was extremely ecstatic when I got my new dog. I felt really ____” and having the model predict “good” for positive (or “bad” for negative).
For a decoder model that has already been trained to predict the next word given an input sequence, this task should be much easier since it has likely seen a similar example already. Indeed, a prompt can be worth hundreds of training examples (Scao et al., 2021), which makes it a massive boon in cases where collecting data is very difficult. While prompting can also be done on encoder-only models and encoder-decoder models, it is much more difficult to do so.
Conclusion
To summarize, you should use each model architecture in the following cases:
- Encoder-Only models should be used when you know exactly how long your output is going to be.
- Encoder-Decoder models should be used when you’re not sure how long your output length is.
- Decoder-Only models should be used if you don’t have a lot of data for your particular task and you know how to use prompting to leverage the model’s existing knowledge.
