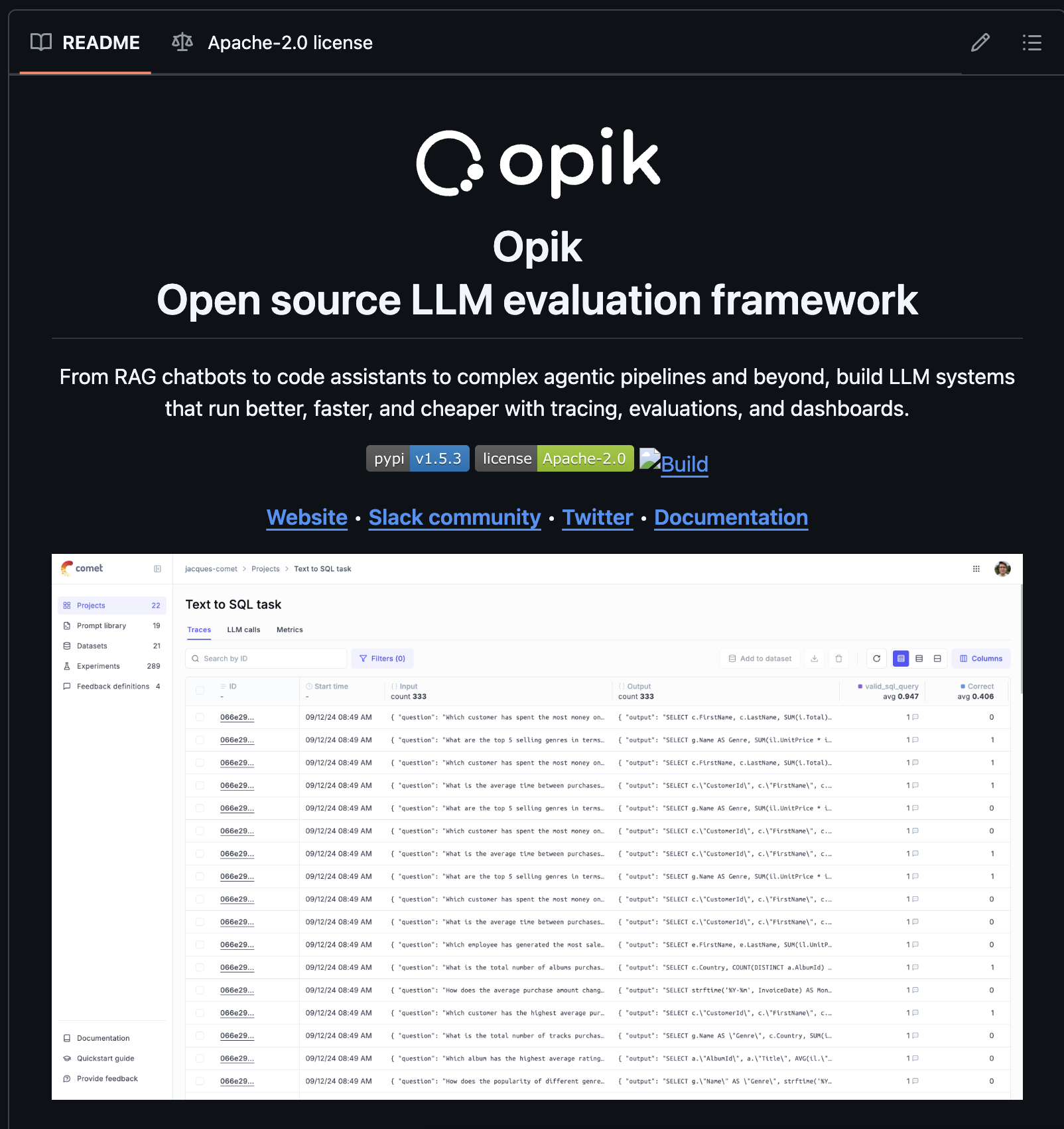
Causal Language Modeling with GPT
Text generation is the task of producing new text. An example of text generation using machine learning is GitHub’s Copilot, which can generate code. Apart from code generation, text generation models can:
- Generate stories, for example, by passing “Once upon a time ” as input to a GPT-2 model.
- Generate music lyrics.
- Generate an entire article.
- Completing incomplete sentences.
- Summarize long documents.
- Translate from one language to another.
Text generation can be achieved using causal language models such as GPT-2. This article will look at how we can fine-tune a causal model with custom data to generate text given a few words.
Causal Language Modeling vs. Masked Language Modeling
Given a sequence of tokens, Causal Language Modeling is the task of generating the next token. It differs from Masked Language Modeling, where certain words in a sentence are masked, and the model is trained to predict them.

In Causal Language Modeling, the model only considers words to the left, while Masked Language Modeling considers words to the left and right. Therefore, Causal Language Modeling is unidirectional, while Masked Language Modeling is bidirectional.

GPT is an example of a pre-trained Causal Language Model, while BERT is an example of a Masked Language Model.
Getting started
In this example, we’ll train a Causal Language Model on the wikitext using GPT. Let’s start by setting up an experiment to track the training process.
import comet_ml
experiment = comet_ml.Experiment(
api_key="YOUR_API_KEY",
project_name="clm", log_code=True,
auto_metric_logging=True,
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
)
Set up a Comet project to track our experiments.
import comet_ml
experiment = comet_ml.Experiment(
api_key="your_API_KEY",
project_name="clm", log_code=True,
auto_metric_logging=True,
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
)
Next, log model parameters to Comet.
# these will all get logged
params = {
"model": "gpt2",
"epochs": 50,
"batch_size": 32,
"learning_rate": 2e-5,
"weight_decay": 0.01,
}
experiment.log_parameters(params)
Tokenize dataset
The text dataset we will be using needs to be converted into a numerical representation. It needs to be converted to a representation that the GPT model expects. Let’s define a function that will tokenize the data using the GPT2Tokenizer.
def tokenize_function(examples):
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(params['model'])
return tokenizer(examples["text"])
Next, define a function that will group the text data and return it in small chunks that are easier to train on as they’ll consume less memory.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
# block_size = tokenizer.model_max_length
block_size = 128
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
Convert data to TensorFlow format
Training the model with TensorFlow requires that the dataset is converted to TensorFlow format. This is done in the following steps:
- Load the dataset using Hugging Face.
- Process the dataset using the tokenized function.
- Apply the
group_textsfunction. - Create a Hugging Face data collator to create batches from the dataset.
- Create training and validation datasets using the
to_tf_datasetfunction.
from datasets import load_dataset
from transformers import DefaultDataCollator
datasets = load_dataset("wikitext", "wikitext-2-raw-v1")
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,)
data_collator = DefaultDataCollator(return_tensors="tf")
train_set = lm_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels"],
shuffle=True,
batch_size=params['batch_size'],
collate_fn=data_collator,)
validation_set = lm_datasets["validation"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels"],
shuffle=False,
batch_size=params['batch_size'],
collate_fn=data_collator,)
When you print the tokenized dataset you will see:
- The input ids
- The attention mask
- Labels
- Number of rows

Given some sentences are longer than others, we have to ensure that they are of the same length. In this case, the model’s maximum length is 1024.

To ensure that all sentences have the same length, we have to truncate longer sentences and pad shorter ones using a padding token. Therefore, we need a way to inform the model to ignore the padding tokens. This is done using an attention mask. The attention mask is a tensor with the same shape as the input_ids. The input_ids are the numerical representation of the sentences. The attention mask contains zeros and ones indicating whether the tokens should be attended to. As a result, the padding tokens will be ignored.
Comet is completely free for academics! Sign up today and get started with just two lines of code.
Define causal language model
With the dataset in the correct format, you can now define the causal language model in TensorFlow. The definition of the causal model is done by instantiating TFAutoModelForCausalLM and passing the desired config. In this case, it’s a pre-trained GPT2 model.
from transformers import AutoTokenizer from transformers import AutoConfig, TFAutoModelForCausalLM from transformers import AdamWeightDecay model_checkpoint = params['model'] config = AutoConfig.from_pretrained(model_checkpoint) gpt2 = TFAutoModelForCausalLM.from_config(config)
Train Causal language model
Since this is a pre-trained model, we train it at a low learning rate to avoid overfitting. Training is done by calling the fit method while passing the training and validation set.
Once training is complete, we evaluate the model on the validation set and log the loss. Causal language models are evaluated using the cross-entropy loss and the perplexity. In this case, we use perplexity. The perplexity is the exponential of the cross-entropy.
import math
learning_rate = params['learning_rate']
weight_decay = params['weight_decay']
optimizer = AdamWeightDecay(learning_rate=learning_rate, weight_decay_rate=weight_decay)
gpt2.compile(optimizer=optimizer)
gpt2.fit(train_set, validation_data=validation_set, epochs=params['epochs'])
eval_loss = gpt2.evaluate(validation_set)
experiment.log_metrics({"eval_loss":eval_loss})
print(f"Perplexity: {math.exp(eval_loss):.2f}")
Comet will log all TensorFlow metrics and hyperparameters automatically.


Comet also creates the histograms of the training process. From these visuals, you can see:
- Histograms for weights and biases
- Histograms for activations
- Histograms for gradients



Test causal language model
Let’s now try and generate some tokens from the trained causal model. This is done by:
- Creating an input sequence.
- Tokenizing the sequence using the same tokenizer that was used for training.
- Call the
generatemethod while passing the tokenized sentence. - Decode the generated sequence to see the sentence.
We also log the input and generated sentences to Comet and eventually end the experiment.
input_sequence = "The ship"
experiment.log_text(input_sequence)
tokenizer_checkpoint = params['model']
tokenizer = AutoTokenizer.from_pretrained(tokenizer_checkpoint)
# encode context the generation is conditioned on
input_ids = tokenizer.encode(input_sequence, return_tensors='tf')
output = gpt2.generate(input_ids,min_length=20)
print("Output:\n" + 100 * '-')
result = tokenizer.decode(output[0], skip_special_tokens = True)
experiment.log_text(result)
experiment.end()
result

Final thoughts
In this article, you have seen how to create a text generation model using Hugging Face and Comet. You can tweak the project by trying other types of language models.
Follow me on LinkedIn for more technical resources.
Resources
Related Articles