BERT is among those developments proposed by the Google research team that shifted machine learning standards by demonstrating outstanding results in NLP tasks like question-answering in chatbot applications, computer translation, language interpretation, next sentence prediction, and much, much more.
Overview
BERT (Bidirectional Encoder representation from Transformers) is an open-source machine learning framework designed to assist computers in comprehending the context of ambiguous language and learn to derive knowledge and patterns from the sequence of words.
What gives BERT an edge over other NLP models is its bidirectional training which is in contrast to the earlier models that looked at a text sequence only in one direction, either from left to right or vice versa. The BERT model is pre-trained using the Wikipedia corpus and the BooksCorpus. It can also be later fine-tuned and adapted to the vocabulary and datasets of our choice.
Introduction of BERT model
BERT is a transformer model that includes an attention mechanism. It learns to derive contextual relations using a series of encoders that derive feature representations or embeddings from the text.
The use of bidirectional training helps BERT stand out from naive language models that fail to derive the features from the text from both directions simultaneously; hence the factor of correlation between words is missing from those modes.
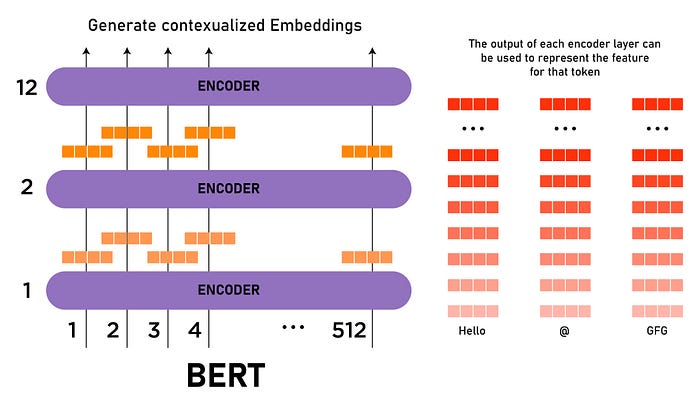
A max_len bounds the input text to the BERT model to train the model. If the value of max_len is set to 512, the 512 tokens will be fed to the input layer padded by tokens if the actual tokens are less than 512 or trimmed if the number of tokens exceeds 512.
Tokenizing sentences and deriving features from the sequence of words longer than the training corpus is very hard to cope with due to the loss of contextual information. In transformers, when the model tries to predict the next word in the sequence, it searches for the positions where the most information is concentrated using the attention blocks. The attention vector acts as a middleman between the input text and the output value. It convolves the input text vector so that some timestamps that have more hidden information are given high importance by masking with 1, else, given no importance, and masked by 0. BERT usually applies self-attention in between the encoder blocks to give importance to important tokens.
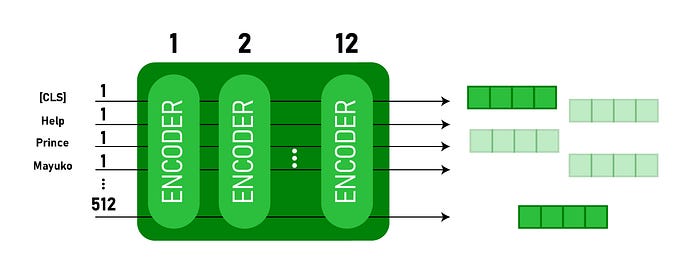
The model takes a CLS token prepended with the input text, which acts as a classification token. Each of the encoder layers applies self-attention mechanism and passes the derived embeddings through a feedforward network. The base version of the model outputs a vector of size 768 which can be used later with a classifier model to predict the corresponding class labels.
Innovation and academia go hand-in-hand. Listen to our own CEO Gideon Mendels chat with the Stanford MLSys Seminar Series team about the future of MLOps and give the Comet platform a try for free!
LSTM vs BERT Transformer model
LSTM is dead, long live transformers 😀
Traditional LSTM models have deeper roots in the NLP world and have been used to solve natural language processing-related tasks. However, LSTMs take more time concerning training the model since they take words sequentially based on timestamps. LSTMs (or rather, RNNs in general), use sequential processing, i.e., processing word-by-word. On the other hand, transformers use non-sequential processing and look at a complete sentence..

On the other hand, transformers have much higher bandwidth and long-term memory. The model predicts the following word in the sequence based on context vectors associated with these source positions and all the previously generated target words with the attention mechanism.
The BERT model, which is deeply based on transformers models, overcomes these two limitations and makes the model faster and deeply bidirectional.
Different learning strategies of BERT
Masked Language Model (MLM)
BERT takes in sentences with random words replaced with [MASK] tokens and uses this as input text. In training, BERT attempts to predict the original text of the words replaced by [MASK] tokens, based on the pattern of other sequences of non-masked words. This helps the model better understand the domain-specific context of the language-model. The end goal of the BERT model is to predict the same sentence that was input, thereby filling in the masked tokens with the original words.
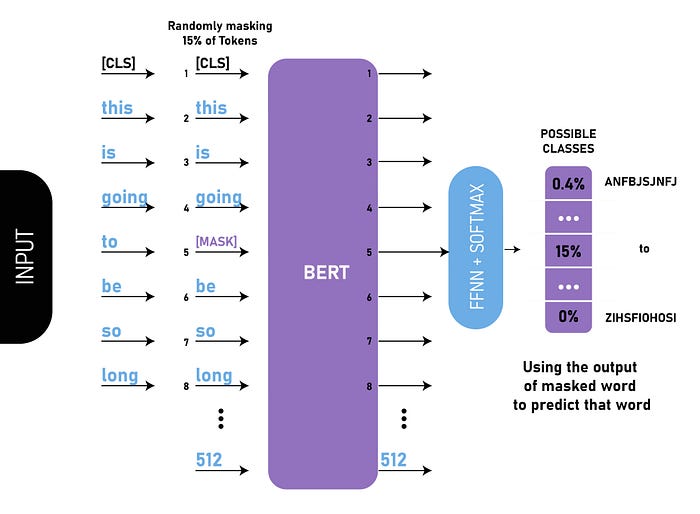
The model uses a ‘softmax’ layer to predict the word from the vocabulary that would best fill in the blank using probability.
Next Sentence Prediction
In this training technique, BERT takes a set of sentences as input and predicts if one sentence will logically follow the other. This helps Bert understand the context across different sentences and applies the attention technique for long-range memory.
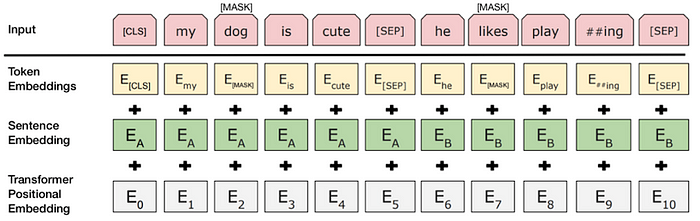
The model distinguishes between the sets of sentences by the use of tokens which are fed to the model in combination with the input set of sentences:
- Two sentences are separated by a [
SEP] token and start with a [CLS] token. - A sentence embedding indicating sentence A/B is mapped to each word of the sentence to understand the correlation between the sentences.
- Each token’s positional embedding is added to indicate its position in the sequence, giving it a bidirectional overview in terms of model training.
The training of the BERT model involves using both the strategies of Masked Language Model and Next Sentence Prediction simultaneously, with the aim of minimizing the cumulative loss function of the two strategies and getting a better understanding of the overall language.
Why are pre-trained models like BERT better for NLP related tasks?
Transfer learning is a technique of re-applying a previously trained ML model on a new task using the past knowledge from a related task in which the model had already been trained before.
The main goal of using a pre-trained model is to solve a similar problem using the derived features from the previously-trained model. Instead of building a model from scratch and going through all the initial stages of training the model, it’s often more efficient to re-use the model trained on another problem as a starting point.
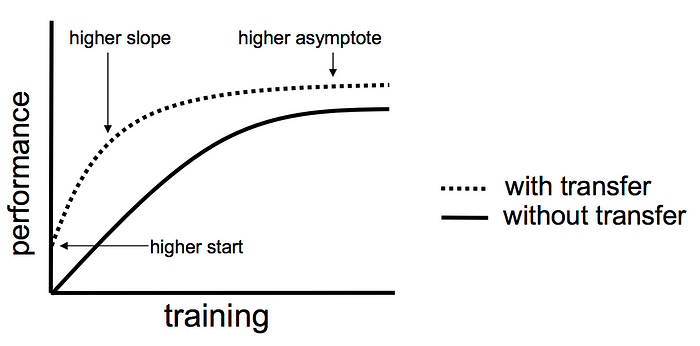
- Higher start: The initial knowledge curve of the base model is already higher than the model trained from scratch.
- Higher slope: The source model’s performance and quality of training, as depicted in the graph, are steeper than they otherwise would be.
- Higher asymptote: The consolidated knowledge of the pre-trained model is better than it otherwise would be.
Fine Tuning BERT model
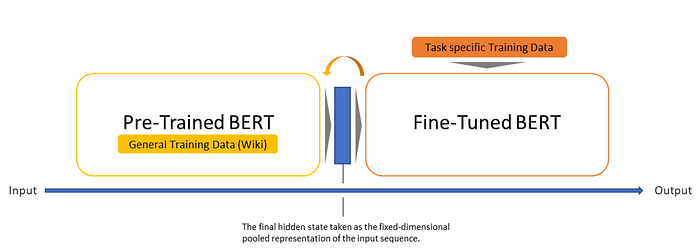
The base version of BERT is trained on the Wikipedia corpus and BooksCorpus. Note that it might require some domain-specific knowledge of the language to use. To achieve this, it’s important to fine-tune the model and provide context to the model so that it performs well in scenarios where domain-specific knowledge is required.
Fine-tuning the model on even a much smaller dataset as compared to the one on which it was originally trained can bring major advantages as well. Depending on your problem at hand, some fine-tuning techniques include:
- Retraining the entire architecture of the model: One can retrain the entire model, which means training all the model’s layers again. The training error/loss is back-propagated through the entire architecture, updating the weights of all the pre-trained layers.
- Train some layers while freezing the others: In this strategy of partial training, one can keep the weights of some layers of the model frozen while retraining only the remaining layers.
- Freeze the entire architecture: One can even think of freezing all the pre-trained layers.
NLP applications where BERT is useful
Below are some NLP applications where BERT has proven to be useful:
- Text classification: As an example, sentiment analysis classifies the text into different categories to measure the positivity/negativity of the sentence.
- Text summarization: BERT is useful for both extractive and abstractive text summarization. By extractive summarization, we mean that important sentences from the text are extracted, and a summary is generated. In abstractive summarization, novel sentences are framed by introducing new words that show similar meaning.
- Smart search engines: With the development of BERT, search engines like Google can better understand the intention and context of search text and provide better and relevant results by analyzing sentences parallelly with maximum self-attention.
- Question answering: The same features can be extended to work as a chatbot.
End Notes
BERT is one of the best performers on a variety of NLP tasks and the credit goes to its bidirectional training strategy. The model is pre-trained, but can learn to apply the patterns of the language for other tasks as well with the use of transfer learning. We can later use this learning to solve simpler tasks like sequence classification or more complex tasks like machine translation, question-answering, etc.
To get a detailed overview do have a look at Google’s original BERT research paper. Another useful reference is the BERT source code and models, which were generously released as open source by the research team.
