AI Emotion Recognition Using Computer Vision

Computer vision is one of the most widely used and evolving fields of AI. It gives the computer the ability to observe and learn from visual data just like humans. In this process, the computer derives meaningful information from digital images, videos etc. and applies this learning tosolving problems.
Visual AI Emotion Recognition
Emotion recognition is one such derivative of computer vision that involves analysis, interpretation, and classification of the emotional quotient using multimodal features like visual data, body language and gestures to assess the emotional state of the person.
Computer’s perception of facial expressions

Facial expressions and human emotions are tightly coupled. So, for machines to be able to understand the meaning of each emotion, it’s important for them to excel in facial detection, and particularly facial landmark detection.

A model is trained to first identify regions of interest from visual images. It is then re-trained to derive patterns of facial expressions using negative and positive values. Genetic algorithms [1] are one way to detect faces in a digital image, followed by the Eigenface technique to verify the fitness of the region of interest. All the valley regions are detected from the gray-scale image to derive high-level facial landmarks like eyes, eyebrows, lips etc.
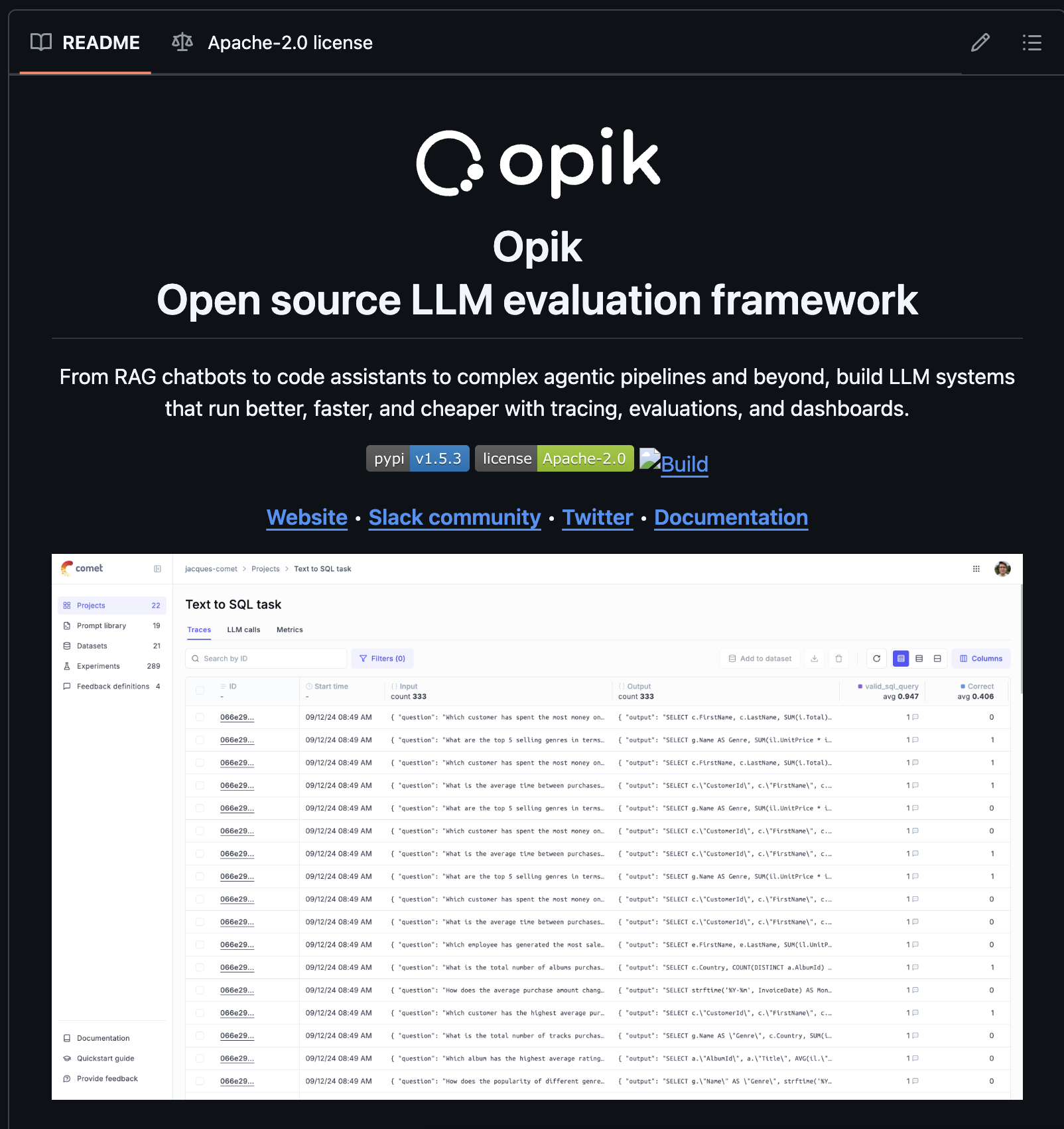
Curious to see how Comet works? Check out our PetCam scenario to see MLOps in action.
Applications of an emotion recognition system
Emotion AI has applications in a variety of fields. Some of these are highlighted below:

- Personalized content and services: Provide personalized content and movie/music recommendations based on the current emotion of the user.
- Customer behavior analysis: Learn from the customer’s emotions and expressions while looking at products/services. Also, some intelligent robots are deployed for behavior-specific advertising.
- Healthcare: Nurse bots that use Emotion AI observe the patient’s condition and converses with them during the treatment for an overall wellbeing.
- Public safety and crime control: Detect the state of a driver or their level of drowsiness and trigger an alert to keep the passengers safe.
- Education: Learning prototypes have been developed and proved efficient in the field of education to adapt to the child’s mood and assess the concentration of the child in a learning environment.
How AI-based emotion analysis works?
On a broader level, the process of emotion recognition can be divided into the following steps:

Data collection
Data is collected by converting video into image sequences by breaking down the frames. Getting a large enough dataset that covers all emotions is difficult, if not impossible, but publicly available open datasets like AffectNet, Emotic, K-Emocon etc. are a good point to start.
Data preprocessing
The image frames are preprocessed by applying techniques like cropping, rotating, resizing, color correction, image smoothening and noise correction to improve the feature vector and the corresponding accuracy of the model.
Training and classification

After pre-processing, we first detect the location of the face (as seen above). Then we detect the facial landmarks (as seen below).

The facial features that are extracted can be measured by Action Units (AU), or the distances between facial landmarks like eyebrow raise distance, mouth opening or gradient features, and more. Regions of interest that show maximum expression changes contain rich facial information. To extract more crucial expression features from the facial expression feature map, an attention module like ECA-Net (Wang et al., 2020) can be integrated to add greater weight to the core features.

The models that are used for AI emotion recognition can be based on linear models like Support Vector Machines (SVMs) or non-linear models like Convolutional Neural Networks (CNNs).
The facial detection model is later fine-tuned to classify the emotional quotient into labels like sadness, happiness, anger, neutral, fear, surprise etc.
Summary
Facial expression recognition is a crucial component of human-computer interaction. The main goal of this recognition system is to determine emotions in real-time, by analyzing the various features of a face such as eyebrows, eyes, mouth, and other features, and mapping them to a set of emotions such as anger, fear, surprise, sadness and happiness. Face detection, feature extraction, and classification are the three key stages that make up the facial expression recognition process. Emotion recognition is being used in many domains, from healthcare to intelligent marketing, to autonomous vehicles, to education.
Thanks for reading!!
Related Articles