Large language models have emerged as ground-breaking technologies with revolutionary potential in the fast-developing fields of artificial intelligence (AI) and natural language processing (NLP). In particular, Large Language Model Operations, or LLMOps, is crucial to the successful deployment, upkeep, and optimization of these powerful models. The way we create and manage AI-powered products is evolving because of LLMs.
What is LLMOps?
The discipline known as “LLMOps,” which stands for “Large Language Model Operations,” focuses on managing the operational aspects of large language models (LLMs). These LLMs are artificial intelligence (AI) systems trained using large data sets, including text and code. Their uses include anything from language translation and text generation to producing creative and content.
The smooth deployment, continuous monitoring, and effective maintenance of LLMs within production systems are major concerns in the field of LLMOps. Solving these concerns entails creating procedures and techniques to guarantee that these potent language models perform as intended and provide accurate results in practical applications.
Understanding the Rise of Large Language Model Operations
The number of LLMs available has significantly increased in recent years. This is brought on by various developments, such as the availability of data, the creation of more potent computer resources, and the development of machine learning algorithms. LLMs have numerous uses, including product development, marketing, and customer service.
LLMs received a lot of media attention when ChatGPT was released in December 2022. Now, more and more organizations are leveraging the power of LLMs, such as:
Programming Assistants: GitHub Copilot, Codium AI, and Socket AI
Chatbots: Google’s Bard, ChatGPT
Writing Assistants: GrammarlyGO, Notion AI, etc
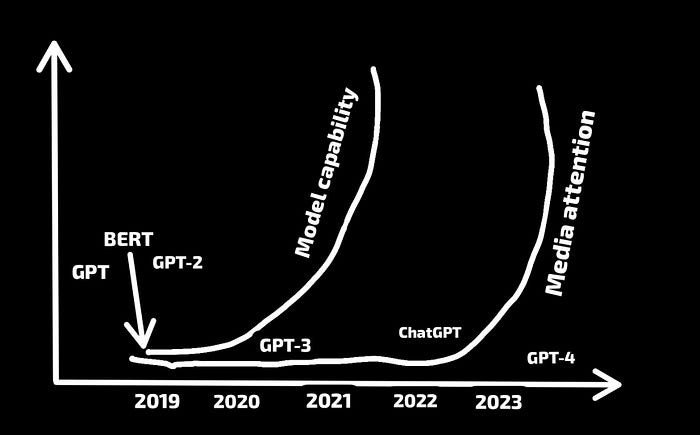
It has become evident that developing applications powered by LLMs suitable for production has different hurdles than developing AI products using traditional ML models. We must create new tools and best practices to manage the LLM application lifecycle to address these issues. As a result, we observe an increase in the use of “LLMOps.”
The LLMOps Steps
LLMs, sophisticated artificial intelligence (AI) systems trained on enormous text and code datasets, have changed the game in various fields, from natural language processing to content generation. Large Language Model Operations incorporates several clearly defined steps and techniques to maximize their potential and guarantee seamless integration into production systems.
Selection of a Foundation Model
The selection of an appropriate foundation model is the first stage in LLMOps. Foundation models are LLMs that have already been extensively trained using massive datasets. This selection procedure considers the model’s architecture, size, and performance on benchmark tasks, among other things. The foundation model of choice serves as the starting point for additional customization to meet the needs of certain downstream activities.
Proprietary Models: Foundation models created and held by certain businesses or groups are known as proprietary models. They are neither open-source nor publicly accessible; therefore, the general public cannot get information on their architecture or training. For a fee, these models are made available through APIs or cloud-based services, enabling enterprises to use their cutting-edge capabilities without handling the supporting infrastructure. However, the exclusivity of these models raises questions regarding their objectivity and transparency.
Open-Source Models: Open-source models are large language models made available to the public with their source code. Researchers, developers, and practitioners can all access, utilize, and modify them. BERT and GPT are examples. Open-source approaches advance the area of artificial intelligence and natural language processing by encouraging openness, cooperation, and innovation. They also make AI capabilities more available to a larger audience.
Adaptation to Downstream Tasks
In LLMOps, “Adaptation to Downstream Tasks” refers to optimizing a large language model (LLM) that has already been trained using task-specific datasets. Due to this fine-tuning, the model becomes more accurate and contextually relevant for use in practical applications, which enables the model to pick up on task-specific nuances. Large Language Model Operations experts can optimize the LLM’s performance and utilize it efficiently across numerous real-world settings without starting from scratch by drawing on the model’s pre-trained information and adapting it to new tasks. You can adapt foundation models to downstream tasks in the following ways:
Prompt Engineering: Prompt engineering is a powerful technique that enables LLMs to be more controllable and interpretable in their outputs, making them more suitable for real-world applications with specific requirements and constraints. It has greatly enhanced the usefulness and dependability of large language models in several downstream tasks and has developed into a crucial step in the fine-tuning procedure.
Fine-Tuning: In LLMOps, the “Adaptation to Downstream Tasks” stage includes a crucial fine-tuning process. A large language model (LLM) that has already been trained, often called the foundation model, is fine-tuned to carry out specific downstream tasks.
Evaluation
A critical phase in LLMOps is LLM evaluation, which entails gauging how well the large language model (LLM) performs on the downstream tasks it is adapted to. This stage involves a detailed analysis of the LLM’s accuracy, effectiveness, and overall capacity to accomplish the desired duties. Different metrics and benchmark datasets are used to assess the LLM. These metrics track how well the model performs across various tasks, including text production, language translation, sentiment analysis, and question-answering. The assessment procedure ensures that the LLM complies with the required quality standards and aids in identifying potential problems like overfitting, underperformance, or biases.
Professionals in LLMOps understand the LLM’s strengths and limitations by thorough examination, which enables them to decide on optimizations, modifications, or prospective upgrades to increase the model’s overall effectiveness. Regular evaluation is also essential for maintaining the LLM’s performance over time, as it can be used to compare different versions or iterations of the model.
Deployment and Monitoring
Deployment and monitoring are essential steps in LLMOps that focus on the effective integration and continuous assessment of the large language model (LLM) in the production environment.
Deployment: The adapted LLM is integrated into this stage’s planned application or system architecture. This includes establishing the appropriate infrastructure, creating communication APIs or interfaces, and assuring compatibility with current systems. Deployment also addresses scalability and reliability concerns to serve user demands while maintaining system stability effectively.
Monitoring: Continuous monitoring is critical once the LLM is implemented. This involves real-time tracking of performance metrics, such as response times, error rates, resource utilization, and user feedback. Monitoring enables LLMOps specialists to spot any abnormalities or deviations from anticipated behavior, allowing for the early discovery and resolution of possible problems. Regular monitoring ensures that the LLM is dependable and operates efficiently during its usage.
LLMOps vs. MLOps: A Comparative Analysis
In this comparative analysis, we explore the differences between LLMOps and MLOps, two independent engineering professions focusing on deploying and managing large language models (LLMs) and standard machine learning models. Organizations may make educated judgments on deploying AI technology successfully to increase innovation and productivity by knowing these disciplines’ distinct concepts and methodologies.
Data Management
Data management in LLMOps entails handling massive datasets for pre-training and fine-tuning large language models. This requires a robust infrastructure and storage capabilities. The data is also subjected to complicated text processing algorithms designed for language-based jobs instead of standard numerical data preprocessing in MLOps. Proper data management enables optimal LLM capacitive performance in language-centric AI applications.
MLOps requires a specialized approach to handle the unique characteristics of textual data and manage large datasets for pre-training and fine-tuning. Focusing on data quality and domain-specific data ensures that the LLM performs optimally in real-world applications. Data privacy and security are equally vital, safeguarding sensitive textual information from potential breaches.
Experimentation
Experimentation in MLOps frequently involves the usage of classic machine learning models. To attain the greatest model performance, data scientists undertake tests by selecting multiple algorithms, hyperparameters, and feature engineering strategies. The experimental phase is often iterative to minimize overfitting, with models trained and assessed on various datasets.
LLMOps, on the other hand, confronts distinct issues because of the complexity of large language models. The experimental procedure might be computationally intensive, requiring significant computer resources to fine-tune an LLM. Large Language Model Operations experimentation entails fine-tuning the pre-trained LLM on task-specific datasets to adapt it to downstream applications.
Evaluation
LLMOps are concerned with assessing LLMs, which are huge, sophisticated models that need significant computational resources to train and deploy. LLMOps frameworks often include tools for monitoring the performance of LLMs, discovering and resolving issues, and ensuring that the models are fulfilling their performance targets.
MLOps, on the other hand, is a broader framework for managing the lifespan of machine learning models. Typically, MLOps systems include capabilities for automating the whole ML lifecycle, from data preparation through model training and deployment. MLOps frameworks, on the other hand, often give less specific help for testing ML models than LLMOps frameworks.
Cost
Due to the resource-intensive nature of training and deploying large language models, Large Language Model Operations often incurs greater initial expenses. However, when demand for AI applications increases, the cost per prediction for LLMs can be lower than traditional machine learning models.
In contrast, MLOps may have cheaper initial infrastructure expenses, particularly for smaller-scale applications. However, as the complexity and size of machine learning models grow, so will the operational costs associated with maintaining and administering these models.
Latency
LLMs are advanced language models known for their extraordinary proficiency in interpreting and creating human-like writing. However, due to their complexity and large size, they have a higher latency than typical machine-learning models. This latency is exacerbated further in fine-tuned LLMs, designed for specific applications and need more processing during inference. As a result, in real-time applications, the increased latency in LLMs can significantly influence user experience, particularly in time-sensitive jobs requiring rapid answers.
MLOps focuses on classical machine learning models, which are smaller and need less processing power than LLMs. These models are built with efficient inference and low latency in mind, making them suited for real-time applications. To reduce inference latency in classic ML models, MLOps teams use optimization techniques like model quantization, pruning, and hardware acceleration.
Summary
As organizations continue to adopt AI technology, Large Language Model Operations emerges as a vital discipline for realizing the full potential of large language models, transforming them into valuable assets for handling complicated language-related tasks. Organizations can navigate the hurdles of LLMOps and harness the potential of LLMs to promote innovation and productivity in the ever-changing world of artificial intelligence by following the concepts presented in this article. Mastering LLMOps will ultimately enable organizations to create cutting-edge AI solutions and open the door for intriguing possibilities in natural language processing and beyond.
