
-
Axios Supply Chain Attack: What Happened, How We Responded, and What You Should Do Right Now
On March 31, 2026, axios — one of npm most popular packages — was compromised with a remote access trojan.…

-
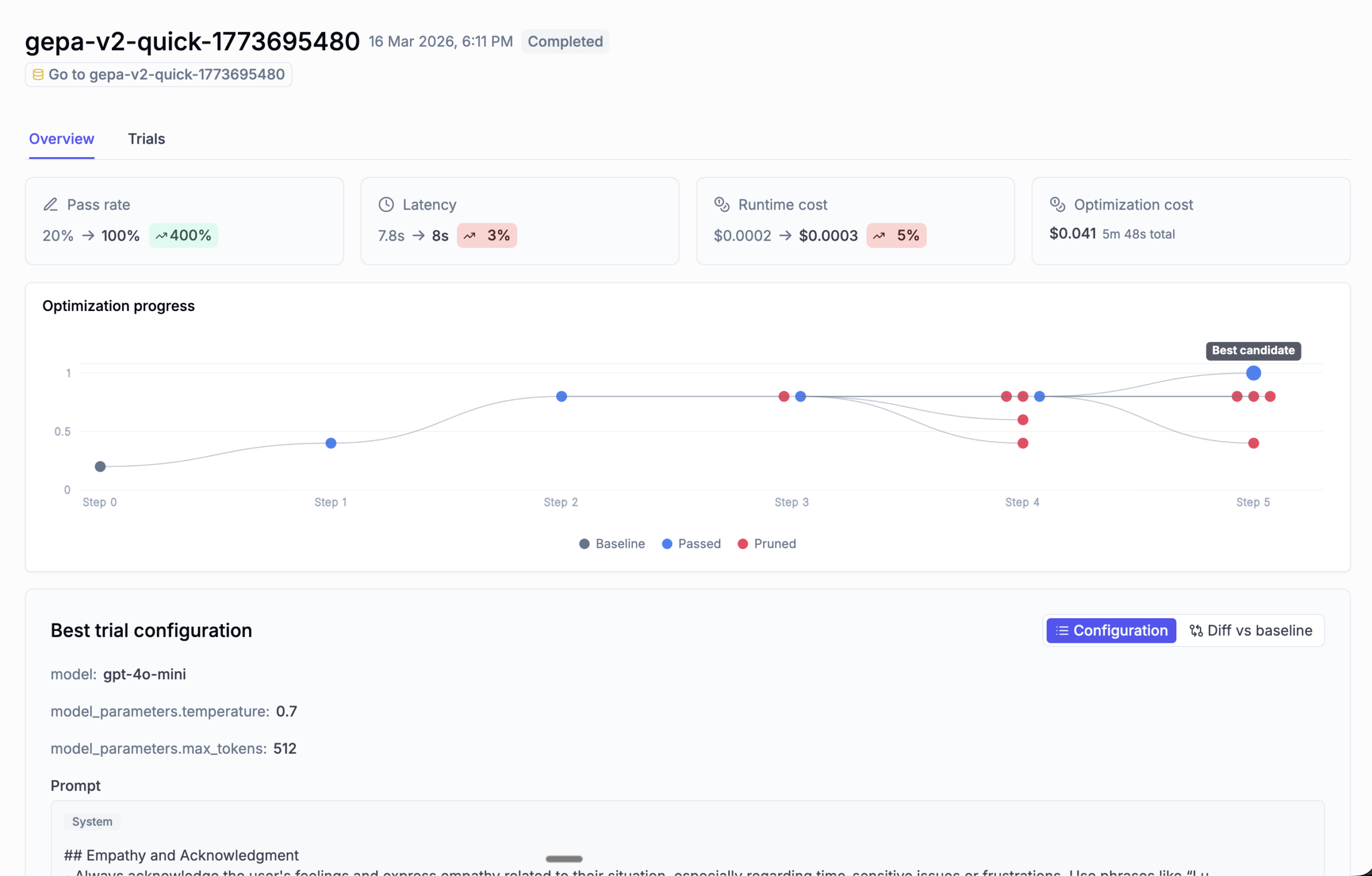
New in Opik: Native OpenClaw Observability, Custom Dashboards, Optimization UI Upgrades, & More!
Whether you’re tracing complex agent workflows, comparing prompt optimization runs, or building dashboards around the metrics that matter most, this…
-
LiteLLM Supply Chain Attack: What Happened, Who’s Affected, and What You Should Do Right Now
LiteLLM — 95 million downloads per month, a dependency of CrewAI, DSPy, Browser-Use, Opik, and nearly every major AI agent…
-
Few-Shot Prompting for Agentic Systems: Teaching by Example
Your new AI agent looks great in testing. It follows instructions, calls tools, and returns clean, structured outputs. Then it…

-
Native Observability & Alerts for Your OpenClaw with Opik
OpenClaw is all the rage, but users want telemetry, observability, and peace of mind to better understand the inner workings…

-
Announcing the Opik Claude Code Plugin: Automatically Configure Observability for Complex Agentic Systems
Agent observability shouldn’t be a side project. But in practice, it is. When teams have to choose between shipping features…

-
LLM Parameter Optimization: Stop Leaving Agent Performance on the Table
If you search for “LLM parameter optimization,” you’ll find guides on tuning learning rates, batch sizes, and layer configurations. But…

-
How to Evaluate RAG Systems: Metrics, Methods, and What to Measure First
When a RAG system fails, the output alone won’t tell you why. RAG stands for retrieval-augmented generation, and it’s one…

-
Retrieval-Augmented Generation: A Practical Guide to RAG Architecture, Retrieval, and Production-Ready Context
Large language models are impressive memorizers. During training, they compress vast amounts of text into billions of parameters, encoding patterns,…

-
Prompt Learning: Using Natural Language to Optimize LLM Systems
Your customers expect better and more consistent results than your AI agent can deliver. You manually tweak a prompt, test…

Comet Blog
-
Announcing the Future of AI Engineering: Self-Optimizing Agents
When ChatGPT launched in 2022, generative AI seemed like magic. With a simple API call and prompt, any application could…








Get started today for free.
You don’t need a credit card to sign up, and your Comet account comes with a generous free tier you can actually use—for as long as you like.