Comet Blog

Meet Opik: Your New Tool to Evaluate, Test, and Monitor LLM Applications
Today, we’re thrilled to introduce Opik – an open-source, end-to-end LLM development platform that provides the observability tools you need…
Today, we’re thrilled to introduce Opik – an open-source, end-to-end LLM development platform that provides the observability tools you need…
Large language models (LLMs) have revolutionized natural language processing, yet most development and evaluation efforts have historically centered around Latin-script…

Detecting hallucinations in language models is challenging. There are three general approaches: Measuring token-level probability distributions for indications that a…

Even ChatGPT knows it’s not always right. When prompted, “Are large language models (LLMs) always accurate?” ChatGPT says no and…

Spring is in the air, and we’re excited to bring you four fresh releases in the Comet platform to make…
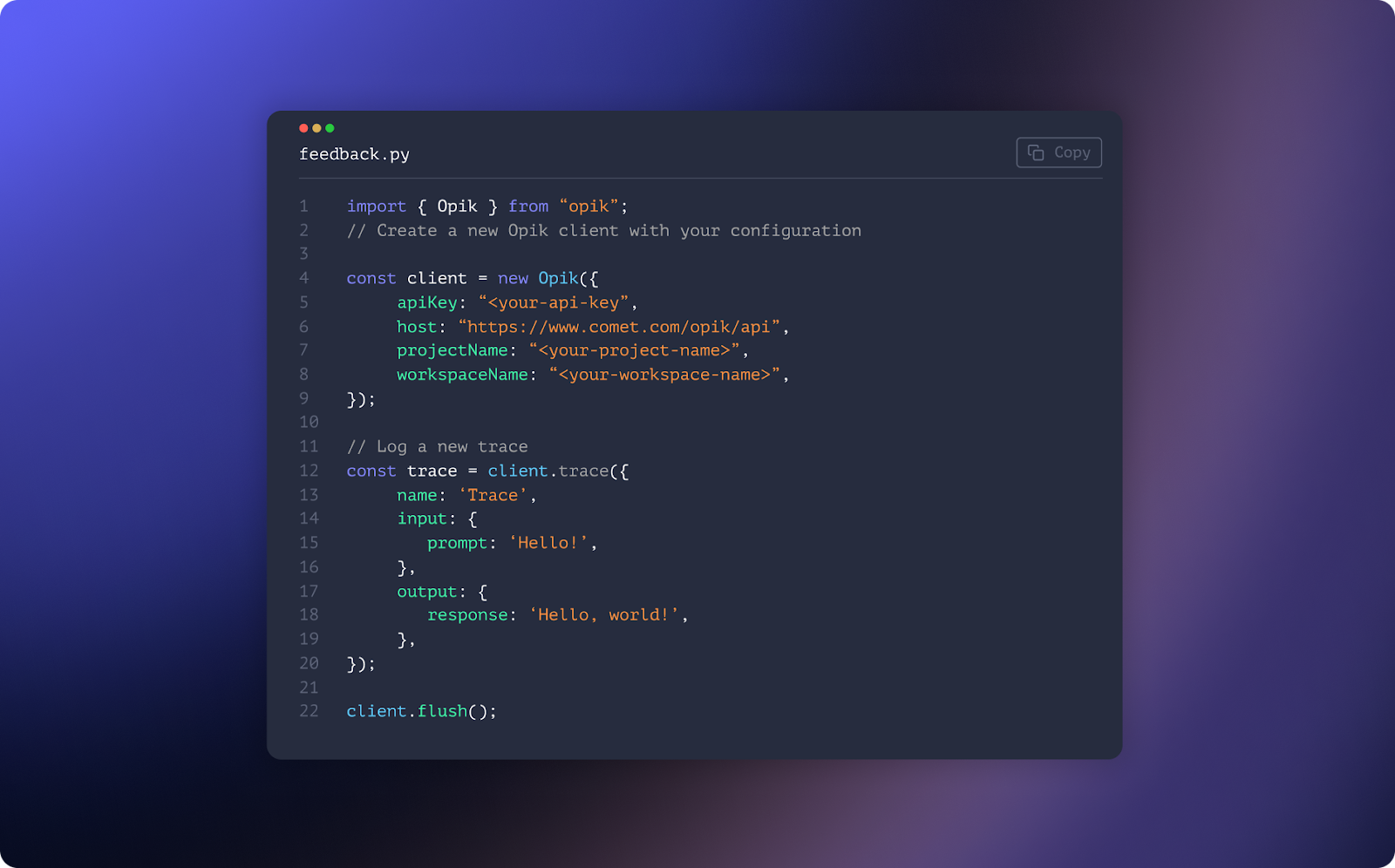
As teams work on complex AI agents and expand what LLM-powered applications can achieve, a variety of LLM evaluation frameworks…

Evaluating the correctness of generated responses is an inherently challenging task. LLM-as-a-Judge evaluators have gained popularity for their ability to…

So, you’re building an AI application on top of an LLM, and you’re planning on setting it live in production.…
