Develop the Best Models with ML Experiment Management
Experiment management is an essential step to getting your MLOps workflow to the next level.
We know the pain of having to double back on experiments to track down which model performed best. With no version tracking, parameter setting, and proper environmental controls, you run the risk of expending more effort on your experiments than you should.
Table of Contents
Introduction: Will this guide be helpful to me?
This guide will be helpful to you if you are:
Know More About Experiment Management
In machine learning, experiment management is the process of tracking, organizing, and making experiment metadata accessible to collaborate on within your organization. These include code versions, data set versions, hyperparameters, environment, and metrics.
By tracking, we mean collecting all the necessary information about your ML experiments that are needed to:
Anatomy of ML Experiments
ML experiments are highly iterative. Teams can get buried in heaps of data sets and code versions before they can even find the ones they are looking for. Experiment tracking helps streamline your current ML workflow.
With Comet Experiment Tracking, you can track the following with just two lines of code:
Simply add two lines of code to start tracking in 30 seconds. Once you set up your tracking system, you can easily compare experiments to understand differences in model performance.
Running ML Experiments
Tracking starts as soon as you add a single line of code. Experiment tracking organizes your model development process, and is essential for repeatability and transparency.
Experiment tracking is when you save all experiment-related information for each experiment that you execute. This “metadata you care about” will vary depending on your project, however, it may comprise the following:
Comparing ML Experiments
Comparing experiment results goes much faster when you already have the data laid out. It’s essential to resolve training runs, generate improvement ideas, or assess your existing best models.
However, if you don’t have an experiment tracking system in place:
Experiment Management Matters
Machine Learning models are becoming increasingly popular as data science teams discover new applications for these models across a wide range of industries and use cases. ML models may be used for practically any use case, from forecasting how quickly a wound would heal to training a model to read and extract text from documents, provided the appropriate data is available.
The early phases of constructing ML models include a lot of hard work in terms of acquiring and comprehending data, modeling the data, and training the model. However, bringing the concept into production has its own set of obstacles. These obstacles may frequently make or ruin your efforts.
Here are four of the most typical issues that teams experience when attempting to deploy an ML model with poor or non-existent experiment management:
What to Keep Track of in ML Experimentations
Racking is the process of gathering all of the metainformation about your ML experiments that are required to:
Here are the pieces of an experiment that must be recorded.
Code Version Control
Code tracking is a common problem amongst machine learning and data science teams.
Issue #1: Jupyter notebook version control
Jupyter notebooks, which contain more than simply code, are used for a substantial portion of data science research. Fortunately, tools exist to assist with notebook versioning and diffing, such as:
Once you’ve versioned your notebook, I’d recommend going the additional mile and ensuring that it runs from top to bottom. You can use jupytext or nbconvert for this.
Issue #2: Experiments on dirty commits
People in data science do not always adhere to the best software development methods. You can always find someone who will ask “How about model monitoring code in the interim between commits?” or “What if someone conducts an experiment but does not commit the code?”
One possibility is to expressly prohibit code execution on unclean commits. Another alternative is to provide users with an extra safety net and snapshot code every time they conduct an experiment. Comet provides the latter in order to preserve the entire experimentation history of the model training process.
Hyperparameters
Hyperparameters have a profound impact on model training success. A simple decimal point change on some parameters can lead to vastly different results. It is important to track hyperparameters during experimentation so you can easily compare the performance of model with different hyper parameter configurations.
Data Versioning
Data in real-world projects changes with time. Typical scenarios include:
When your data changes, the outcome of your analysis, report, or experiment findings will most likely change, even if your code and environment remain untouched. That’s why, to compare apples to apples, you must maintain track of your data versions.
Not having your data versioned while obtaining various outcomes may be highly annoying, resulting in a lot of lost work (and, ultimately, money). The unfortunate aspect is that there is little you can do about it afterward. So make sure to keep your experiment data versioned, once again.
Artifacts
Artifacts allow you to maintain track of assets outside of any single experiment. You can track Artifact versions, build a variety of assets, manage them, and utilize them at each stage of your ML workflows, from training to production deployment.
ML Metrics
Keeping track of your experiments and ensuring the reproducibility of your work is an important piece of the puzzle. After tracking hundreds of experiment runs, you will quickly run into new issues, such as:
As such, it’s critical to track assessment metrics for your machine learning models to:
Pro tip: Since metrics you care about may change in a real-world project, it’s better to log more metrics than you think you need. It will save you time in the future and help you get to new discoveries.
Best Practices for ML Experiment Management
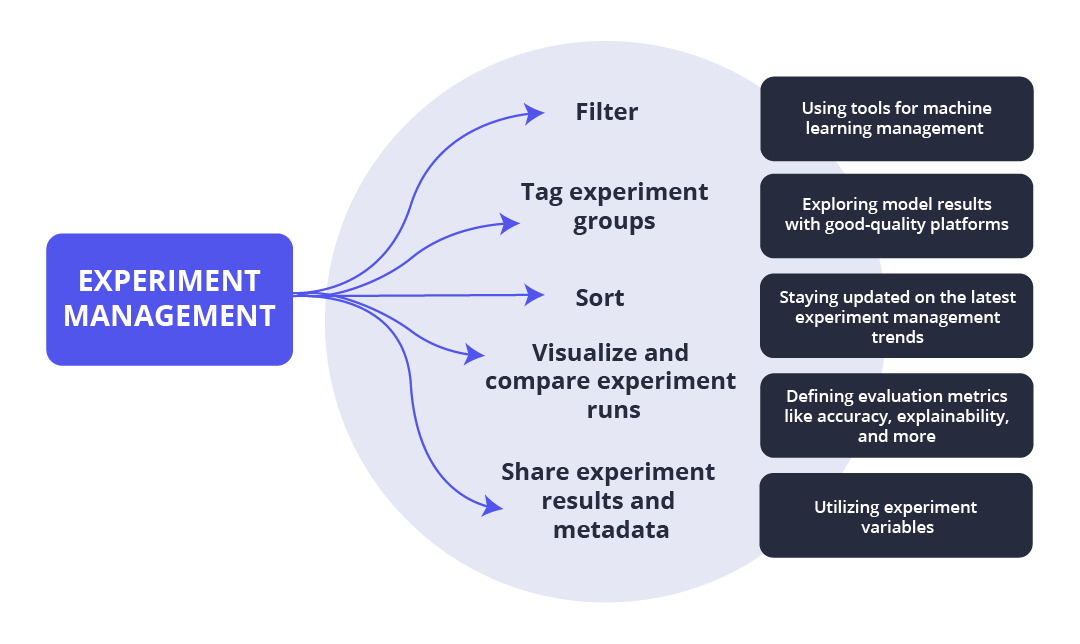
Experiment management software allows you to filter, sort, and tag experiment groups, visualize and compare experiment runs, and share experiment results and metadata. Other best practices include:
Frequently Asked Questions (FAQs)
The Experiment Management component allows you to track and display machine learning experiments, log various information, search and compare experiments, assure model repeatability, work on ML projects as part of a team, and much more.
ML model management simplifies the transition of models from experimental to production, aids in model versioning, and organizes model artifacts in an ML model registry.
DevOps is used in software development to reduce the barriers between development and operations. DevOps brings together the people, processes, and technology required to coordinate the development of software and eliminate the silos that often separate teams.
Here’s a quick guide to managing your machine learning experiments:
- Make a hypothesis and conduct an experiment.
- Define the experimental variables.
- Experiment datasets, static parameters, and metadata are all tracked.
- Make trials and start training jobs.
- Experiment findings are being analyzed.
Comet is one of the most popular MLOps platforms for teams deploying machine learning algorithms. Trusted by tens of thousands of data scientists across the Fortune 100, including companies like Uber, Autodesk, Zappos, and Ancestry. A self-hosted or cloud-based machine learning platform, Comet includes a Python library that allows data engineers to integrate code and manage the entire MLOps lifecycle across your entire project portfolio.
The best practices in ML experiment management in 2022 include:
In practice, AI analytics helps in automating much of the labor traditionally performed by a data analyst in the ML experiment management process.
Some of the best tools to use for ML experiment management are:
ML experiment management can help ML teams understand data sets and code versions in an organized way before they find the ones they’re looking for. Overall, experiment tracking helps teams streamline their current ML workflows, preserves the context of model training, and allows teammates to communicate efficiently with each other
The number and types of training data sets that help improve the model’s performance are determined by the complexity of the issue and learning algorithms, model competence, data size evaluation, and the usage of statistical heuristic rules.
Learn More
Wondering how to implement MLOps and experiment management best practices to increase the efficiency of your ML team? Read the comprehensive MLOps guide to learn more and boost your ML project performance.