SelfCheckGPT for LLM Evaluation
Detecting hallucinations in language models is challenging. There are three general approaches:
- Measuring token-level probability distributions for indications that a model is “confused.” Though sometimes effective, these methods rely on model internals being accessible—which is often not the case when working with hosted LLMs.
- Referencing external fact-verification systems, like a database or document store. These methods are great for RAG-style use-cases, but they are only effective if you have a useful dataset and the infrastructure to use it.
- Using LLM-as-a-judge techniques to assess whether or not a model hallucinated. These techniques are becoming standard in the LLM ecosystem, but as I’ll explain throughout this piece, using them effectively requires a deceptive amount of work.
The problem with many LLM-as-a-Judge techniques is that they tend towards two polarities: they are either too simple, using a basic zero-shot approach, or they are wildly complex, involving multiple LLMs interacting via multi-turn reasoning.
SelfCheckGPT offers a reference-free zero-resource alternative: a sampling-based approach that fact-checks responses without external resources or intrinsic uncertainty metrics. The key idea is consistency—if an LLM truly “knows” a fact, multiple randomly sampled responses should align. However, if a claim is hallucinated, responses will vary and contradict each other.

Detecting Hallucinations Via Consistency
There are several varieties of SelfCheckGPT, but all share a general basic structure:
- First, a user asks a question, and the AI gives an answer.
- SelfCheckGPT then asks the same AI the same question multiple times and collects several new responses.
- It compares the original answer to these new responses.
- If the answers are consistent, the original response is likely accurate.
- If the answers contradict each other, the original response is likely a hallucination.
To quantify this, SelfCheckGPT assigns each sentence a hallucination score between 0 and 1:
- 0.0 means the sentence is based on reliable information.
- 1.0 means the sentence is likely a hallucination.
The major advantage to this approach is that it provides a practical way to assess factual reliability without external dependencies or internal model access. It uses a consensus mechanism that is reminiscent of ensemble techniques, like LLM juries, but it only requires the use of a single model.
SelfCheckGPT also benefits from being an extremely flexible framework. We’ll explore this in the next section, but you can easily imagine many different approaches to assessing “agreement” between answers.
An Overview of SelfCheckGPT Approaches
The different types of SelfCheckGPT are variations of the same general framework for detecting hallucinations in LLMs, but each uses a unique method to measure response consistency. The original SelfCheckGPT paper described the following five methods:
- SelfCheckGPT with BERTScore: This variant evaluates the factuality of a sentence by comparing it to similar sentences from multiple sampled responses using the BERTScore metric. For each sentence, the maximum BERTScore between it and the most similar sentence in each sample is averaged. If the sentence is consistent across many samples, it’s considered factual; if not, it may be a hallucination. This approach uses RoBERTa-Large to compute the BERTScore.
- SelfCheckGPT with Question Answering (QA): This approach generates multiple-choice questions using MQAG based on the main response and then compares the answers from different samples. If the answers are consistent, the sentence is considered valid; if they diverge, it indicates a potential hallucination.
- SelfCheckGPT with an N-gram Model: Here, a simple n-gram model is trained using multiple samples to approximate the LLM’s token probabilities. The likelihood of each sentence is then computed to detect inconsistencies. A higher log-probability suggests consistency, while lower probabilities may indicate hallucination.
- SelfCheckGPT with Natural Language Inference (NLI): This method uses an NLI model (DeBERTa-v3-large) to assess whether a sampled response contradicts the sentence being evaluated. The NLI model classifies the relationship as either entailment, neutral, or contradiction, and only the contradiction score is used for the evaluation. The higher the contradiction score, the more likely the sentence is inconsistent or a hallucination.
- SelfCheckGPT with Prompting: In this variant, an LLM is prompted to assess if a sentence is supported by a sample response. Based on the answer (Yes or No), an inconsistency score is computed. This approach is effective with models like GPT-3.
In this tutorial, we’ll be focusing on the three most popular variants: SelfCheckGPT-BERTScore, SelfCheckGPTMQAG, and SelfCheckGPTLLMPrompt.
SelfCheckGPT with BERTScore
SelfCheckGPT with BERTScore is the most popular variant due to its speed, low memory usage, and computational efficiency. To better understand how SelfCheckGPT works under the hood, we’ll first implement this variant from scratch. Once we’ve gained that insight, we’ll use the selfcheckgpt module’s built-in implementation of three variants to automatically evaluate a dataset using Opik.
Follow along with the full code in the Colab if you aren’t already!
In this section, we’ll assume that we already have the original generated output (which we are evaluating) as well as the stochastically generated additional outputs (to which we are comparing our original output). We’ll cover how to incorporate this step into your workflow a little later on. For now, let’s just focus on what the metric is doing under the hood.

Given our original generated output, passage, and a list of 3 additional generated passages, samples, we’ll need to:
- Break down the original passage into individual sentences with SpaCy
- Prepare an empty array to serve as our comparison matrix between the sentences in the original passage and each additional sample. As such, the dimensions of this array should be
num_sentencesxnum_samples. - Define two functions:
- Creates a new list where each individual sentence from the original passage is repeated the number of times equal to the number of sample sentences. For example: [“Cat”, “Dog”] would become [“Cat”, ”Cat”, ”Cat”, “Dog”, ”Dog”, ”Dog”]
- Creates a list where the entire list of sample sentences is repeated the number of times equal to the number of sentences in the original passage. For example: [“Cat”, “Dog”] would become [“Cat”, ”Dog”, ”Cat”, ”Dog”, ”Cat”, ”Dog”]
- For each additional sample:
- Break it down into sentences
- Compare it to every sentence in the original passage with the two functions defined above
- Calculate the BERTScore between these paired sentences (BERT embeddings via RoBERTa-Large → cosine similarity)
- Reshape the scores into a matrix where each row represents an original sentence and each column represents a sample sentence.
- For each original sentence, find the highest similarity score across all sample sentences – essentially finding the “best match” for each original sentence within this sample passage.
- Store the best-match scores in a column of the results matrix, with each row representing an original sentence
- After processing all sample passages, the code averages the scores across all samples to get a final similarity score for each original sentence, which is then inverted (1 – score) to represent dissimilarity.
- This process returns a list of scores for each sentence in the original passage, as per the original paper. For our purposes, we’ll just return the max score in this list of scores, which represents the highest likelihood that a given sentence in the passage is a hallucination.
def evaluate_sentences_with_bertscore(
original_passage: str,
sampled_passages: List[str],
nlp=None,
language: str = "en",
rescale_with_baseline: bool = True
) -> np.ndarray:
"""
Evaluate sentences against sampled passages using BERTScore.
This function computes the semantic similarity between each input sentence and
sentences from multiple sampled passages using BERTScore. For each input sentence,
it finds the best matching sentence within each sample and averages these scores.
Args:
original_passage: Original passage to be evaluated
sampled_passages: List of reference passages to compare against
nlp: Spacy NLP model for sentence tokenization (if None, loads en_core_web_sm)
language: Language model to use for BERTScore
rescale_with_baseline: Whether to rescale BERTScore with baseline
Returns:
np.ndarray: Array of dissimilarity scores (1 - BERTScore) for each input sentence
"""
# Initialize spaCy if not provided
if nlp is None:
nlp = spacy.load("en_core_web_sm")
sentences = [sent for sent in nlp(original_passage).sents] # List[spacy.tokens.span.Span]
sentences = [sent.text.strip() for sent in sentences if len(sent) > 3]
# Prepare dimensions
num_sentences = len(sentences)
num_samples = len(sampled_passages)
bertscore_matrix = np.zeros((num_sentences, num_samples))
# Helper functions for list expansion
def expand_list_per_element(source_list: List[str], repeat_count: int) -> List[str]:
"""Repeat each element in source_list repeat_count times."""
return [item for item in source_list for _ in range(repeat_count)]
def expand_list_whole(source_list: List[str], repeat_count: int) -> List[str]:
"""Repeat the entire source_list repeat_count times."""
return [item for _ in range(repeat_count) for item in source_list]
# Process each sample passage
for sample_idx, sample_passage in enumerate(sampled_passages):
# Split passage into sentences using spaCy
sample_sentences = [sent.text.strip() for sent in nlp(sample_passage).sents]
num_sample_sentences = len(sample_sentences)
# Prepare comparison pairs
references = expand_list_per_element(sentences, num_sample_sentences)
candidates = expand_list_whole(sample_sentences, num_sentences)
# Calculate BERTScore (precision, recall, F1)
_, _, f1_scores = bert_score.score(
candidates,
references,
lang=language,
verbose=False,
rescale_with_baseline=rescale_with_baseline
)
# Reshape and extract maximum scores
f1_matrix = f1_scores.reshape(num_sentences, num_sample_sentences)
max_f1_scores = f1_matrix.max(axis=1).values.cpu().numpy()
# Store scores for this sample
bertscore_matrix[:, sample_idx] = max_f1_scores
# Calculate mean BERTScore across all samples
mean_bertscore_per_sentence = bertscore_matrix.mean(axis=1)
# Return dissimilarity score (1 - similarity)
return 1.0 - mean_bertscore_per_sentence
We can then test our function on a few sampled outputs. We can call this function on a factual passage and a hallucinated passage and compare their scores on the same samples to see the difference.
selfcheckgpt_bertscore_factual = evaluate_sentences_with_bertscore(original_passage=passage,
sampled_passages=[sample_1, sample_2, sample_3])
selfcheckgpt_bertscore_hallucinated = evaluate_sentences_with_bertscore(original_passage=hallucination_passage,
sampled_passages=[sample_1, sample_2, sample_3])
SelfCheckGPT-BERTScore with Opik
Now that we’ve gained some intuition for what’s going on under the hood, we can use the selfcheckgpt module to create a custom Opik evaluation metric and automatically evaluate a dataset. If you aren’t already, you can follow along with the Colab here.
In this section, we’ll use OpenAI’s GPT-4o via LiteLLM to answer a list of questions without any ground truth references, external context, or criteria. We’ll then randomly generate three additional responses from GPT-4o and compare them to the original response.
After setting up our environment, we’ll start by defining our model and logger. We’ll also load the small English language model from spaCy, which will be used for sentence tokenization in our scoring metric.
import litellm
from litellm import completion
from litellm.integrations.opik.opik import OpikLogger
from opik import track
import spacy
opik_logger = OpikLogger()
litellm.callbacks = [opik_logger]
MODEL = "gpt-4o"
SYSTEM_PROMPT = "Answer the question as truthfully as possible in no more than six sentences."
sentence_model = spacy.load('en_core_web_sm')
We’ll define a simple function to generate our original response from GPT-4o, as well as an evaluation function which calls our application function and returns the output in the format expected by our pipeline later on. We decorate them both with the track decorator so that all of the details of the calls are automatically logged to Opik.
# Define the LLM application with tracking
@track
def generate_answer(question: str) -> str:
response = litellm.completion(
model=MODEL,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": question},
],
)
return response.choices[0].message.content
@track
def evaluation_task(data):
llm_output = generate_answer(data['question'])
return {"question": data['question'],
"answer": llm_output,
"model_name": MODEL,
"system_prompt": SYSTEM_PROMPT}
We’ll use the selfcheckgpt module’s implementation of SelfCheckGPT-BERTScore to create a custom Opik metric by subclassing the base_metric.BaseMetric class and implementing a score method.
Note that we’ll need to use the same model specified in the MODEL variable above to create three additional output samples. We then loop through these samples to determine their consistency with the original output generated by our generate_answer function.
from typing import Any
from opik.evaluation.metrics import base_metric, score_result
import selfcheckgpt
from selfcheckgpt.modeling_selfcheck import SelfCheckBERTScore
import spacy
class SelfCheckGPTBERTScore(base_metric.BaseMetric):
def __init__(self, name: str = "SelfCheckGPT", model_name: str = "gpt-4o", language: str = "en", nlp = sentence_model):
self.name = name
self.model_name = model_name
self.language = language
self.opik_logger = OpikLogger()
self.selfcheck_bertscore = SelfCheckBERTScore()
self.nlp = nlp
def score(self, question: str, answer: str, model_name: str, system_prompt: str, num_samples: int = 3, **ignored_kwargs: Any):
"""
Score the output of an LLM.
Args:
question: The question asked to the LLM.
answer: The answer from the LLM to score.
model_name: Name of the model to use for generating samples.
system_prompt: System prompt to use for generating samples.
num_samples: Number of additional samples to generate for comparison.
**ignored_kwargs: Any additional keyword arguments.
"""
# Generate num_samples # of additional responses
litellm.callbacks = [self.opik_logger]
samples = []
for samp in range(num_samples):
response = litellm.completion(
model=model_name,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": question}
]
)
samples.append(response.choices[0].message.content.replace("\n", " ").strip())
sentences = [sent for sent in self.nlp(answer).sents]
sentences = [sent.text.strip() for sent in sentences if len(sent) > 3]
sent_scores_bertscore = self.selfcheck_bertscore.predict(
sentences,
samples)
return score_result.ScoreResult(
name=self.name,
value=max(sent_scores_bertscore)
)
SelfCheckGPT with MQAG
BERTScore isn’t the only way to use SelfCheckGPT, however. Another popular variety is SelfCheckGPT-MQAG (Multiple-choice Question-Answer Generation).
This approach generates multiple-choice questions using the MQAG model based on the main response and then compares the answers from different samples. If the answers are consistent, the sentence is considered valid; if they diverge, it indicates a potential hallucination.
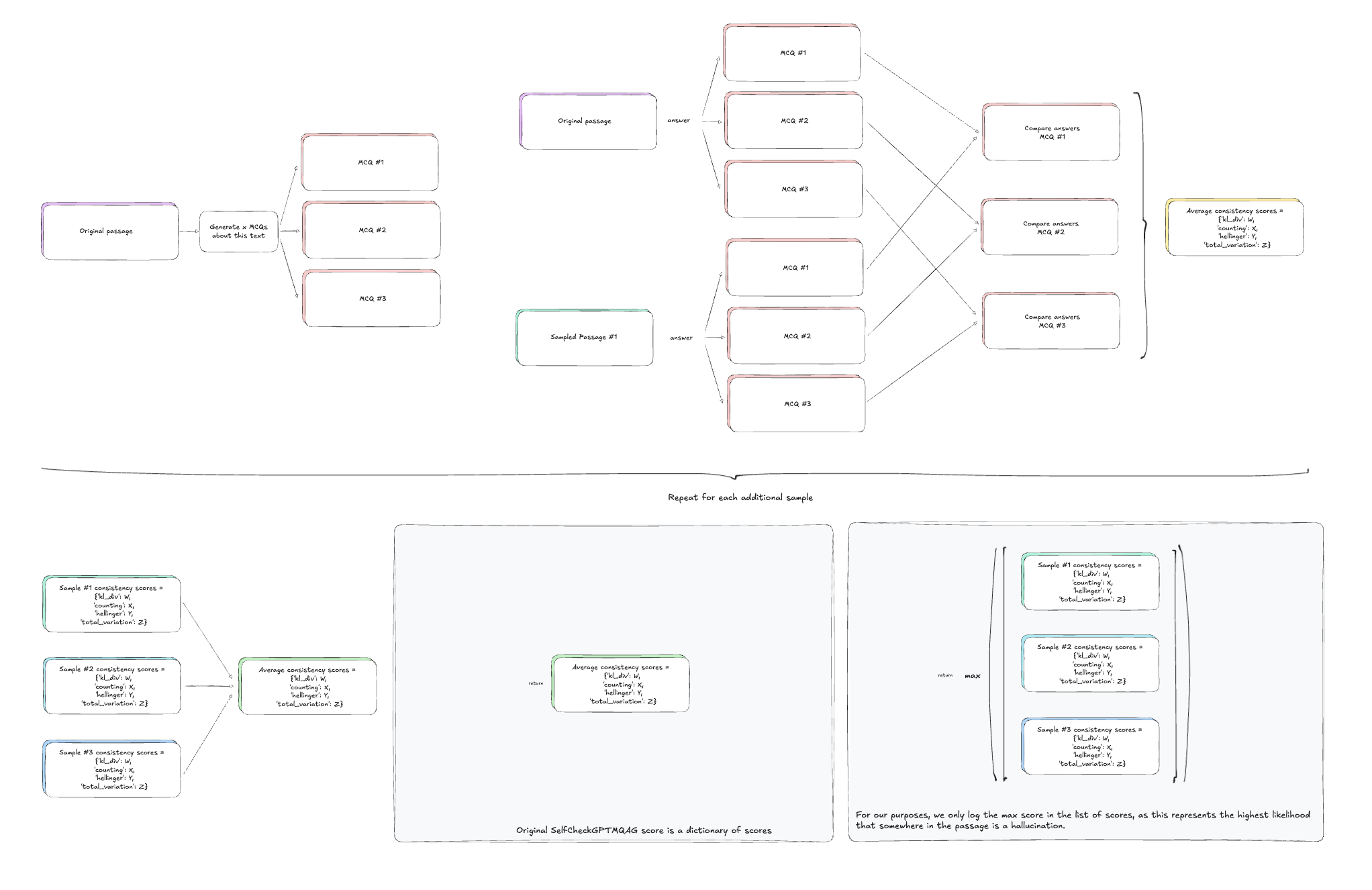
A dictionary is returned containing the Kullback-Leibler divergence, mismatch count, Hellinger distance, and total variation. For our use case we’ll simply take the max total variation, as this represents the maximum likelihood that somewhere in the passage is a hallucination.
from typing import Any
from opik.evaluation.metrics import base_metric, score_result
import selfcheckgpt
from selfcheckgpt.modeling_mqag import MQAG
import spacy
import torch
class SelfCheckGPTMQAG(base_metric.BaseMetric):
def __init__(self, name: str = "SelfCheckGPTMQAG", model_name: str = "gpt-4o", language: str = "en", nlp = sentence_model):
self.name = name
self.model_name = model_name
self.language = language
self.opik_logger = OpikLogger()
self.nlp = nlp
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.selfcheck_mqag = MQAG(device=self.device)
def score(self, question: str, answer: str, model_name: str, system_prompt: str, num_samples: int = 3,
num_questions: int = 3, **ignored_kwargs: Any):
"""
Score the output of an LLM using MQAG with CUDA acceleration.
Args:
question: The question asked to the LLM.
answer: The answer from the LLM to score.
model_name: Name of the model to use for generating samples.
system_prompt: System prompt to use for generating samples.
num_samples: Number of additional samples to generate for comparison.
num_questions_per_sent: Number of questions to generate per sentence.
**ignored_kwargs: Any additional keyword arguments.
"""
# Generate num_samples # of additional responses
litellm.callbacks = [self.opik_logger]
samples = []
for _ in range(num_samples):
response = litellm.completion(
model=model_name,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": question}
]
)
samples.append(response.choices[0].message.content.replace("\n", " ").strip())
var_scores = []
for sample in samples:
score = self.selfcheck_mqag.score(candidate=sample, reference=answer, num_questions=3, verbose=True)
var_scores.append(score["total_variation"])
return score_result.ScoreResult(
name=self.name,
value=max(var_scores)
)
SelfCheckGPT with LLM Prompting
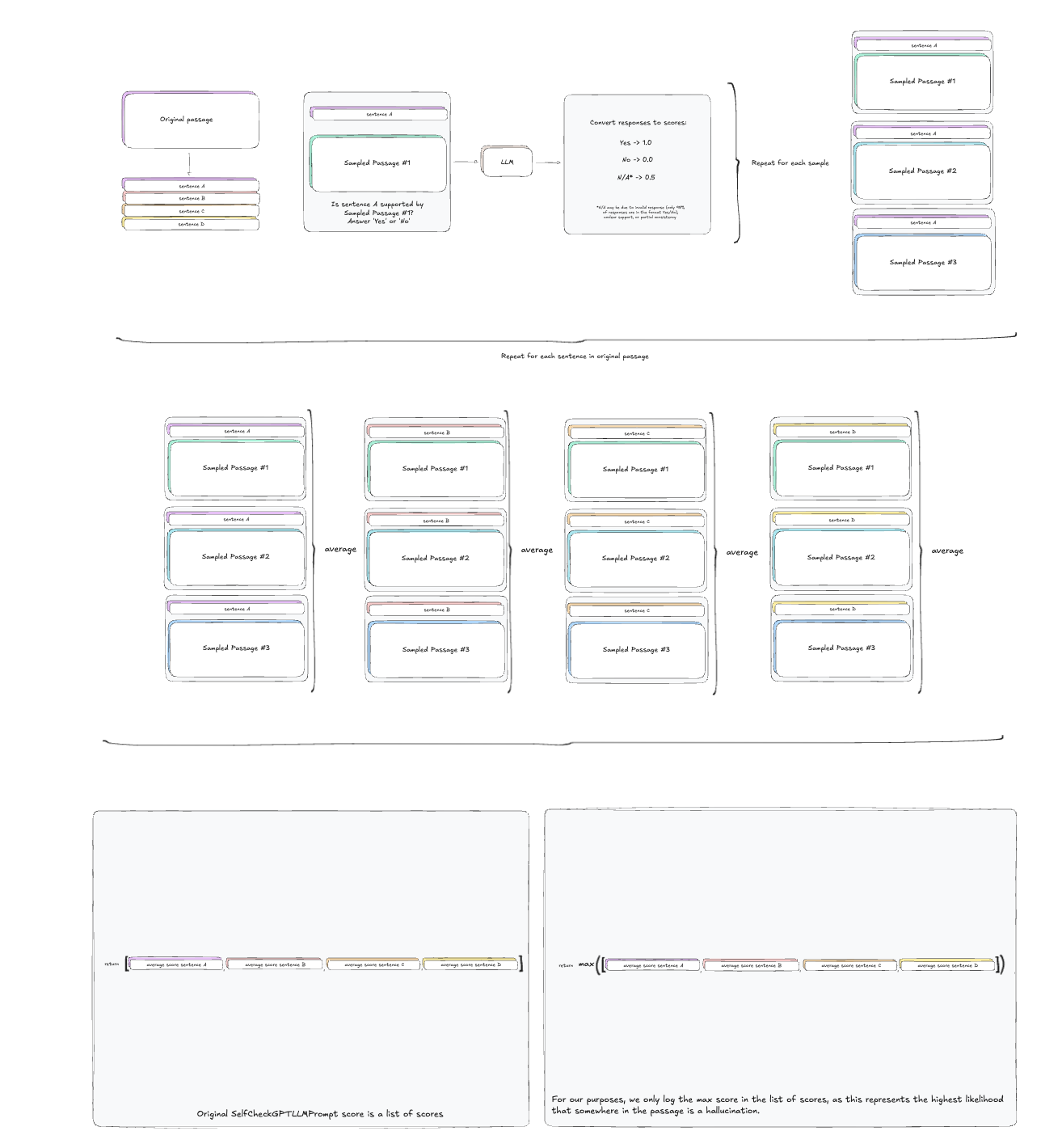
In this variant, an LLM is prompted to assess if a sentence is supported by a sample response. Based on the answer (Yes or No), an inconsistency score is computed. This approach is effective with models like GPT-3.
from typing import Any
from opik.evaluation.metrics import base_metric, score_result
import selfcheckgpt
from selfcheckgpt.modeling_selfcheck_apiprompt import SelfCheckAPIPrompt
import spacy
class SelfCheckGPTAPIPrompt(base_metric.BaseMetric):
def __init__(self, name: str = "SelfCheckGPTAPIPrompt", model_name: str = "gpt-4o", language: str = "en", nlp = sentence_model):
self.name = name
self.model_name = model_name
self.language = language
self.opik_logger = OpikLogger()
# API access currently only supports client_type="openai"
self.selfcheck_prompt = SelfCheckAPIPrompt(client_type="openai", model=self.model_name)
# Load spacy model only once
self.nlp = spacy.load("en_core_web_sm")
def score(self, question: str, answer: str, model_name: str, system_prompt: str, num_samples: int = 3,
num_questions: int = 3, **ignored_kwargs: Any):
"""
Score the output of an LLM using MQAG with CUDA acceleration.
Args:
question: The question asked to the LLM.
answer: The answer from the LLM to score.
model_name: Name of the model to use for generating samples.
system_prompt: System prompt to use for generating samples.
num_samples: Number of additional samples to generate for comparison.
num_questions_per_sent: Number of questions to generate per sentence.
**ignored_kwargs: Any additional keyword arguments.
"""
# Generate num_samples # of additional responses
litellm.callbacks = [self.opik_logger]
samples = []
for _ in range(num_samples):
response = litellm.completion(
model=model_name,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": question}
]
)
samples.append(response.choices[0].message.content.replace("\n", " ").strip())
sentences = [sent.text.strip() for sent in self.nlp(answer).sents]
sent_scores_prompt = self.selfcheck_prompt.predict(sentences=sentences, # list of sentences
sampled_passages=samples, # list of sampled passages
verbose=False, # whether to show a progress bar
)
return score_result.ScoreResult(
name=self.name,
value=max(sent_scores_prompt)
)
Automating Evaluation with Opik
Now, let’s put it all together and run our three varieties of SelfCheckGPT on a toy dataset. We can create a simple list of questions, which we upload to Opik:
questions = [
"Who was Ernst Opik?",
"How big was the Spanish Armada?",
"What is the Great Wall of China?",
"Do honeybees sleep?",
"What are asteroids made of?",
"How does a starfish move?",
"What did Marie Curie do?",
"What did the sixth president of the United States accomplish?",
"When is the best time to launch a rocket?",
"Where is the largest man-made structure located?"
]
from opik import Opik
# Log dataset to Opik
client = Opik()
dataset = client.get_or_create_dataset(name="SelfCheckGPT-dataset")
dataset.insert(
[{"question": q} for q in questions])
Then, to use our three SelfCheckGPT metrics, we simply instantiate them and pass them as a list to the scoring_metrics parameter of the opik.evaluation.evaluate function:
SelfCheckGPTBERTScore = SelfCheckGPTBERTScore()
SelfCheckGPTMQAG = SelfCheckGPTMQAG()
SelfCheckGPTAPIPrompt = SelfCheckGPTAPIPrompt()
from opik.evaluation import evaluate
# Perform the evaluation
evaluation = evaluate(
experiment_name="My SelfCheckGPT Experiment",
dataset=dataset,
task=evaluation_task,
scoring_metrics=[SelfCheckGPTBERTScore,
SelfCheckGPTMQAG,
SelfCheckGPTAPIPrompt],
task_threads=1
)
Once this has finished running, your results should look something like this:
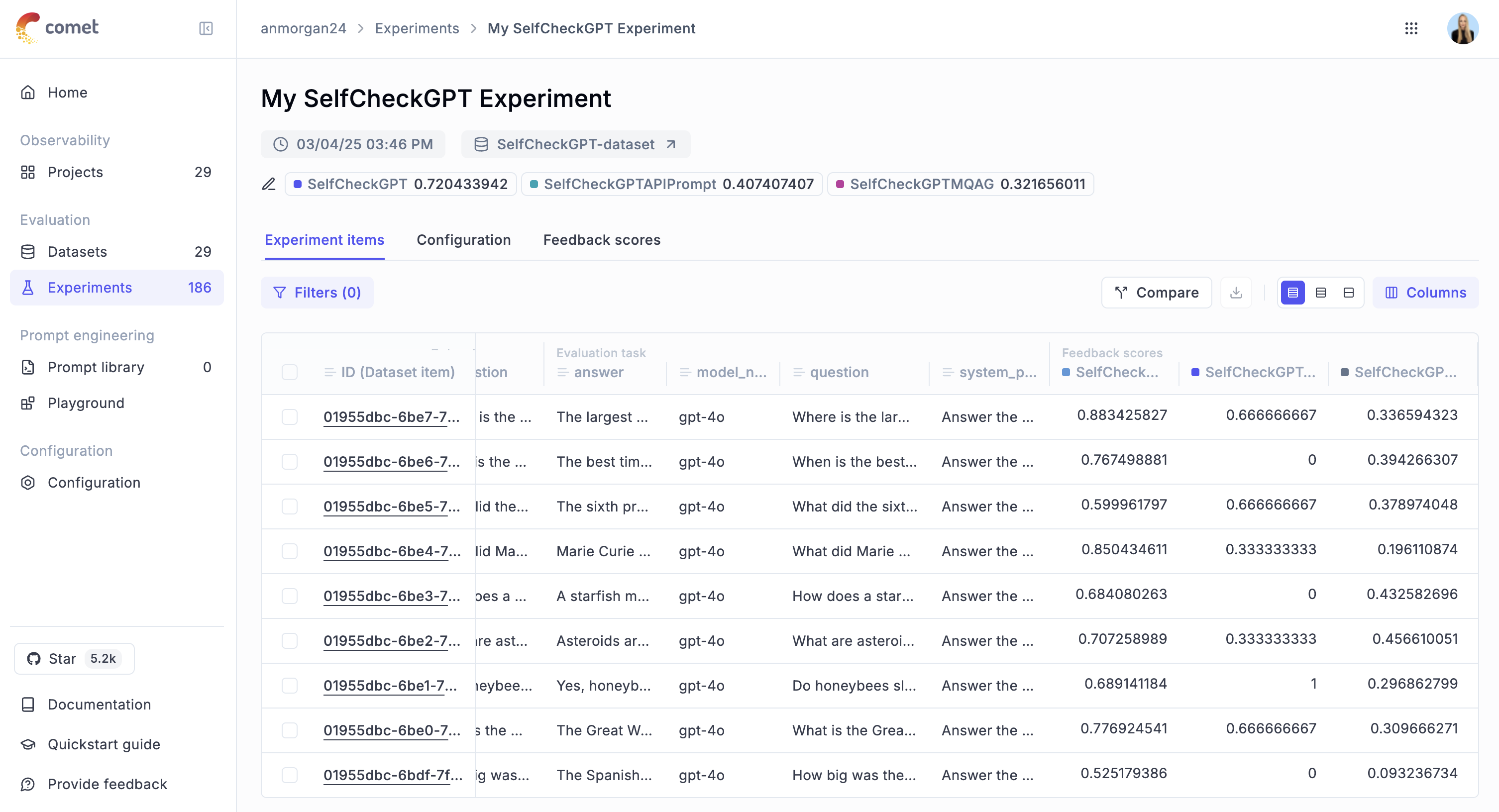
Advantages and Limitations of SelfCheckGPT
SelfCheckGPT offers a reference-free, zero-resource alternative for evaluating the factuality of LLM outputs, but it comes with some notable limitations.
A major drawback is its computational overhead. SelfCheckGPT requires multiple sampled generations per input, leading to significant costs. While some components (e.g., multiple generations) can be parallelized across GPUs, others, like BERTScore similarity computations, have sequential dependencies that limit speedups. For instance, using MQAG, processing a small dataset of ten questions takes over ten minutes on a T4 GPU, which severely limits scalability.
Another limitation stems from its core assumptions. SelfCheckGPT relies on the idea that true facts will appear more frequently across sampled generations. But this doesn’t always happen in practice and if a model consistently generates the same hallucinated information, it could incorrectly classify it as factual. This is especially problematic if the model has learned false knowledge from biased or incorrect training data. To this end, if a model is biased towards certain types of answers, SelfCheckGPT may inadvertently reinforce that bias.
Despite these limitations, SelfCheckGPT remains a valuable tool for hallucination detection. It offers a flexible, domain-agnostic approach that, while computationally expensive, can be more cost-effective than human annotation and works without references or external resources or databases. Its strengths make it particularly useful in high-stakes domains that demand both factual accuracy and scalability, representing a step toward more reliable and trustworthy AI.
If you found this article useful, follow me on LinkedIn and X/Twitter for more content!
Related Articles


