LLM Juries for Evaluation
Evaluating the correctness of generated responses is an inherently challenging task. LLM-as-a-Judge evaluators have gained popularity for their ability to provide nuanced, reference-free, and scalable assessments across diverse tasks. However, individual models still suffer from biases, inconsistencies, and blind spots.
Ensemble learning, a long-standing technique in traditional machine learning, enhances accuracy and robustness by aggregating multiple models. This principle applies to LLM evaluation workflows as well. So-called LLM Juries– panels of diverse LLM judges– leverage ensembling to improve accuracy, fairness, and interpretability, offering a more robust and reliable evaluation framework.
In this article, we’ll explore the advantages and limitations of LLM Juries and how to implement one from scratch in Opik.
What is an LLM Jury?
An LLM Jury consists of multiple LLM judges that independently score a given output, then aggregate their scores through a voting function. Unlike a single LLM-as-a-Judge evaluator, which often relies on a large model like GPT-4o, an LLM Jury typically consists of smaller models from distinct families (e.g., GPT, Claude, Command R, Mistral).
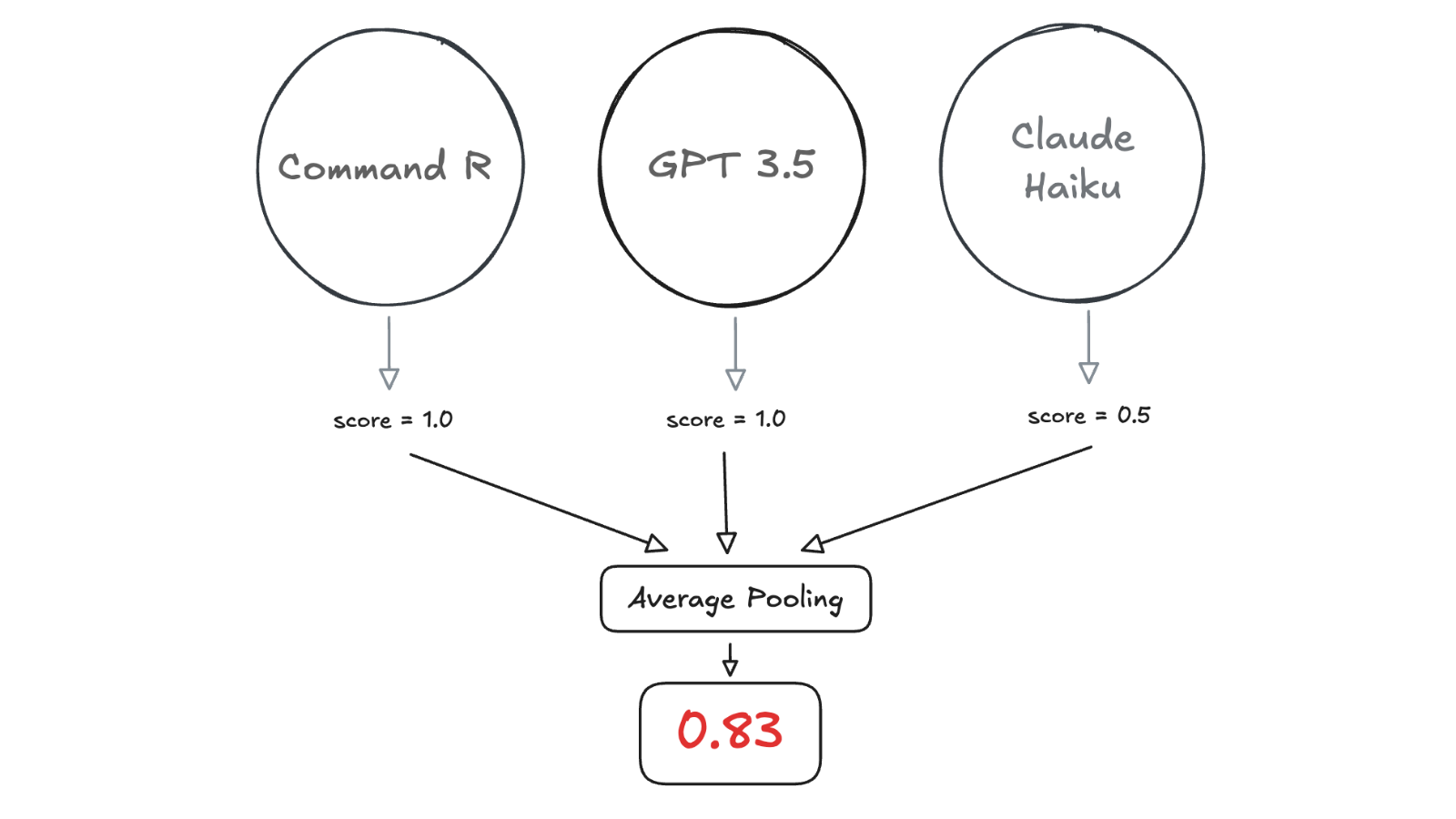
While larger models handle diverse evaluation tasks well, some smaller or fine-tuned models may struggle with generalization. For this reason, each (smaller) model in the jury should support the required scoring type, for example reference-based scoring, or pair-wise scoring.

LLM Juries use traditional ensemble learning techniques for score aggregation, depending on the task. For example, max pooling may be appropriate for binary classification, average or median pooling may be appropriate for rating scales, soft or hard voting for binary or multi-class classification, or stacking for open ended evaluations.
Why Use a Jury Instead of a Judge?
A single large model like GPT-4o is often used as an evaluator due to its generalizability, depth of knowledge, and reasoning capabilities. However, this approach has significant drawbacks.
If the same model generates and evaluates responses, self-recognition can lead to self-preference, introducing bias and reducing evaluation fairness. This intra-model bias is a serious issue in safety-critical and ethical applications, and can also affect baseline performance.
Ultra-large models are also expensive and slow due to their high computational requirements. This makes them unsuitable for many real-time, edge, or large-scale applications.
Research from Cohere suggests that a diverse panel of smaller models outperforms a single large judge, reduces bias, and does so at over 7x lower cost. Additionally, multiple smaller models can run in parallel, further improving speed and efficiency.
Implementing LLM Juries in Opik
Using what we’ve learned so far about LLM Juries, let’s implement one as a custom metric in Opik. Follow along in the full-code Colab if you aren’t already!
For this tutorial, we’ll be using a toy subset of the Natural Questions (NQ) dataset created by Google Research and available in the Hugging Face datasets module. It consists of two fields:
question: Input open domain question (str)answer: List of possible answers to the question (list)

Next, we’ll select the model to be evaluated and define the evaluation task. Here, we use Qwen2.5-3B-Instruct, since it easily fits within a Colab notebook and is readily available in Hugging Face’s transformers module.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load the model and tokenizer
MODEL_NAME = "Qwen/Qwen2.5-3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
We write a very simple function that accepts as input the question from our NQ dataset and returns the model’s response. By adding the track decorator, we ensure that everything is automatically tracked to Opik.
from opik import track
@track
def generate_answer(input_question: str) -> str:
"""Generates an answer based on the input question using the loaded LLM."""
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": input_question}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
We’ll also add the track decorator to our evaluation task, which simply calls the function we defined above and returns it in the appropriate format for the evaluate function we’ll call later on.
@track
def evaluation_task(data):
"""Evaluates the LLM output given a dataset sample."""
llm_output = generate_answer(data['question'])
return {"output": llm_output}
For our particular use case, we want each of the models in our jury to return structured outputs in the form of valid JSON objects. This way, we can ensure that each model returns its output in the same format and we can easily aggregate the scores. For this, we’ll use OpenAI’s structured formats and define our response_format:
# JSON schema for hallucination scoring response_format
RESPONSE_FORMAT = {
"type": "json_schema",
"json_schema": {
"name": "hallucination_score",
"strict": True,
"schema": {
"type": "object",
"properties": {
"score": {
"type": "number",
"description": "A hallucination score between 0 and 1"
},
"reason": {
"type": "string",
"description": "The reasoning for the assessed hallucination score"
}
},
"required": ["score", "reason"],
"additionalProperties": False
}
}
}
Next, we’ll define our LLM Jury metric as a custom metric using Opik’s BaseMetric class.
Creating Our LLM Jury Custom Metric
First, we define a prompt which will be passed to each of the models in our jury. We make sure to specify the single-point scoring task and evaluation criteria and use a form-filling paradigm.
"""
You are an impartial judge evaluating the following claim for factual accuracy. Analyze it carefully
and respond with a number between 0 and 1: 1 if completely accurate, 0.5 if mixed accuracy, or 0 if inaccurate.
Then provide one brief sentence explaining your ruling.
The format of the your response should be a JSON object with no additional text or backticks that follows the format:
{{
"score": <score between 0 and 1>,
"reason": "<reason for the score>"
}}
Claim to evaluate: {output}
Response:
"""
For simplicity’s sake, we will use OpenRouter to call each of the models in our jury. OpenRouter is a unified API service that provides access to multiple AI models through a single standardized interface. This way we will have uniform input and output formatting from each model and can simply loop through a list of our model names. For a full list of models supported by OpenRouter, see here. Note that we have selected models from three distinct model groups, namely OpenAI, Mistral AI, and Cohere. We opted not to use Anthropic’s Claude Haiku, as in the original paper, because it does not support JSON schema response format.
model_names = ["openai/gpt-4o-mini", "mistralai/mistral-small-24b-instruct-2501", "cohere/command-r-08-2024"]
Next we define the score method of our LLMJuryMetric class. The score method should return a ScoreResult object with a value and a name.
In our case, our score method loops through our list of models and uses our prompt to evaluate Qwen2.5-3B-Instruct’s answer to the question from our dataset. The method checks to make sure a valid JSON object is returned and collects the responses in a list called completions. The response scores are then pooled using an average function, along with a dictionary of the reasons for those scores. Later, we can choose to set a rule for the result of the average function, like:
is_hallucination = avg_score >= 0.5
For now, though, let’s take a look at our scores and we can set a threshold later on.
Let’s put it all together in our custom Opik metric LLMJuryMetric:
from opik.evaluation.metrics import base_metric, score_result
from opik.evaluation import models
import json
from typing import Any
from openai import OpenAI
from opik.integrations.openai import track_openai
import numpy as np
class LLMJuryMetric(base_metric.BaseMetric):
"""Metric to evaluate LLM outputs for factual accuracy using multiple models and an avergae voting function."""
def __init__(self, name: str = "LLM Jury"):
self.name = name
self.llm_client = track_openai(OpenAI(base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),)
)
self.prompt_template = """
You are an impartial judge evaluating the following claim for factual accuracy. Analyze it carefully
and respond with a number between 0 and 1: 1 if completely accurate, 0.5 if mixed accuracy, or 0 if inaccurate.
Then provide one brief sentence explaining your ruling.
The format of the your response should be a JSON object with no additional text or backticks that follows the format:
{{
"score": ,
"reason": ""
}}
Claim to evaluate: {output}
Response:
"""
self.model_names = ["openai/gpt-4o-mini", "mistralai/mistral-small-24b-instruct-2501", "cohere/command-r-08-2024"]
def score(self, output: str, **ignored_kwargs: Any):
"""
Score the output of an LLM.
Args:
output: The output of an LLM to score.
**ignored_kwargs: Any additional keyword arguments. This is important so that the metric can be used in the `evaluate` function.
"""
# Construct the prompt based on the output of the LLM
prompt = self.prompt_template.format(output=output)
completions = []
for model in self.model_names:
try:
completion = self.llm_client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": prompt
}
],
response_format=RESPONSE_FORMAT
)
response_data = json.loads(completion.choices[0].message.content)
completions.append(response_data)
except (json.JSONDecodeError, AttributeError, IndexError):
print(f"Error parsing response from model {model}: {completion}")
continue # Skip this model if an error occurs
if completions:
avg_score = np.mean([float(response["score"]) for response in completions])
reasons = {self.model_names[i]: response["reason"] for i, response in enumerate(completions)}
else:
avg_score = 0.0
reasons = "No valid responses received."
return score_result.ScoreResult(
name=self.name,
value=avg_score,
reason=str(reasons)
)
Evaluating With Opik
To use our custom LLMJuryMetric, we simply instantiate it and pass it to the scoring_metrics parameter of opik.evaluation.evaluate:
# Instantiate our custom LLM Jury metric
LLMJuryMetric = LLMJuryMetric()
from opik.evaluation import evaluate
# Perform the evaluation
evaluation = evaluate(
experiment_name="My LLM Jury Experiment",
dataset=dataset,
task=evaluation_task,
scoring_metrics=[LLMJuryMetric],
task_threads=1
)
And here is what the output of your evaluation should look like from within the Opik UI:

Limitations of LLM Juries
Despite their advantages, LLM Juries come with several trade-offs. Managing multiple models is inherently more complex than using a single evaluator. Models from different families often have incompatible input/output formats, requiring additional preprocessing and infrastructure. If each model specializes in evaluating a different criterion, the system must be carefully designed to handle diverse evaluation strategies, further increasing complexity.
Smaller models also underperform in reasoning tasks compared to larger counterparts. If these models lack diverse training data, bias mitigation may be minimal, potentially undermining one of the key motivations for using a jury. Since many modern LLMs share similar datasets, finding sufficiently diverse models can be challenging. The additional engineering overhead required to integrate multiple models must be weighed against the expected improvements in evaluation quality.
Cost considerations have also evolved. Token prices have dropped significantly since the original PoLL paper, making the claim that LLM Juries are “7–8x cheaper” than a single large model potentially outdated. While a jury of smaller models is still likely more cost-efficient, the savings may not always justify the added complexity of implementation.
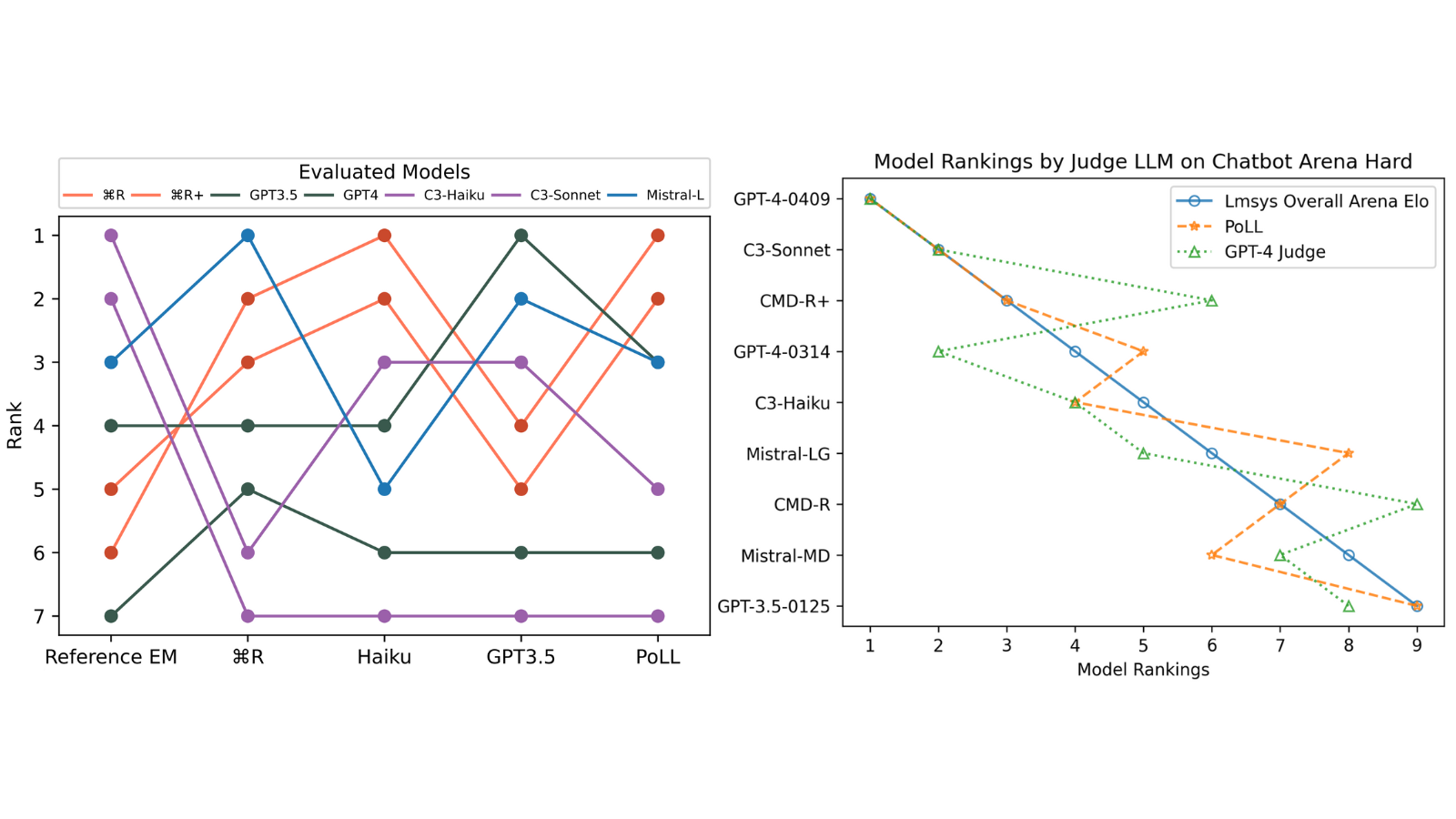
Furthermore, some researchers have questioned PoLL’s findings, particularly its conclusion that GPT-3.5 outperforms GPT-4. The study focused on relatively simple tasks (Single-Hop QA, Multi-Hop QA, and Chatbot Arena Hard), leaving open the possibility that a single large model could still outperform an LLM Jury on more complex, nuanced evaluations.
The Case for LLM Juries
Still, the idea that an ensemble of different models can outperform a single larger model is well established both in research and industry. Mixture-of-Experts approaches have been at the forefront of LLM leaderboards for some time now, as an example. At Comet, we can anecdotally say that, after working with hundreds of teams, we have seen many instances where LLM jury techniques have been the optimal approach for evaluations, outperforming single-model judges. With the introduction of platforms like Opik and OpenRouter, there’s no reason not to experiment with an LLM jury approach inside your evaluation pipelines.
If you found this article useful, follow me on LinkedIn and Twitter for more content!
Related Articles


