Building Opik: A Scalable Open-Source LLM Observability Platform

Opik is an open-source platform for evaluating, testing, and monitoring LLM applications, created by Comet. When teams integrate language models into their applications, they need ways to debug complex systems, analyze performance, and understand how their development work affects responses returned by an LLM in terms of accuracy, relevance, context awareness, and other qualities. The platform they use to log, evaluate, and iterate on this work needs to be both user friendly and highly scalable, and accommodate many distinct tasks and use cases.
To build Opik, the Comet team tapped into decades of combined experience training, deploying, and monitoring machine learning models, with the goal of making data science workflows more accessible to teams building with LLMs.
In this post, we’ll share the Comet engineering team’s perspective on building Opik, exploring the architectural decisions and technical details that enable Opik to provide robust tracing, evaluation, and production monitoring capabilities.
While our focus is on how Opik’s architecture supports state-of-the-art LLM evaluation, the underlying design patterns and technologies can serve as a reference for many other production systems.
Key Requirements
Opik’s development was shaped by several key requirements:
- Accessibility: The easiest way to use Opik is by creating a free account on comet.com.
- Open-source and easy deployment:
- Opik is designed as a fully open-source, self-contained application. It can be installed and run on a single host with minimal setup.
- Users can also deploy Opik on their own infrastructure using production-ready Kubernetes Helm Charts.
- Fast iterations and rapid feedback: Since customers asked for a solution quickly, our team’s goal was to launch early, then iterate based on user feedback.
- State-of-the-art architecture and technology: Opik adopts a service-oriented architecture, with each component focusing on a specific functionality.
- It relies on proven, highly-scalable open-source systems like ClickHouse, MySQL, Redis, and Nginx.
- It’s implemented using reliable languages, frameworks, and libraries such as Python, Java with Dropwizard, and TypeScript with React.
- Scalability: Opik supports up to 100,000 traces per month under professional plans, with unlimited traces under enterprise plans.
- Core Functionality: Opik addresses core aspects of LLMOps: tracking LLM calls and traces, automating LLM evaluation, collecting and monitoring feedback scores, and token usage over time.
- Usability: Opik’s user interfaces emphasize a positive user experience, improved continuously through community feedback and iterative design.
Challenges and Solutions
One prominent challenge in building Opik was the unpredictable nature of LLM calls and traces, which create multiple types of concurrent events (traces, spans, feedback scores, dataset items, experiment items, etc.). These events often arrive in unexpected order, making data consistency trickier.
Addressing these challenges required balancing tradeoffs. The nature of data generated by LLM applications indicated that Opik should be built as an eventually consistent system. Performance and scalability take precedence over strict consistency in Opik’s architecture, which led us to carefully select technologies that meet these performance requirements.
This is why Opik leverages:
- ClickHouse: for large-scale data ingestion and fast queries (e.g., for traces or experiments).
- MySQL: for data that demands ACID properties, such as projects or feedback definitions requiring transactional guarantees.
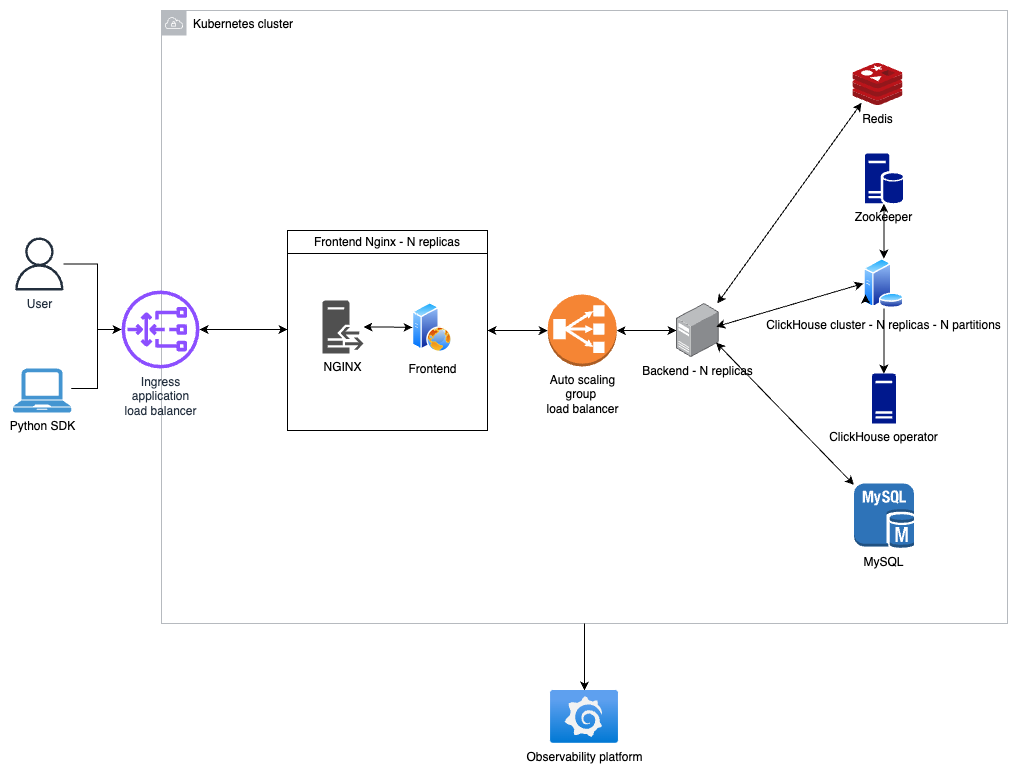
High-Level Architecture
Opik’s architecture consists of multiple services that each handle a specific role, including:
- A backend service: Java + Dropwizard.
- A frontend application: TypeScript + React, served by Nginx.
- Data stores:
- ClickHouse for large-scale data.
- With Zookeeper to coordinate the cluster.
- With an Operator to provide operational and performance metrics.
- MySQL for transactional data.
- Redis for caching, rate limiting, distributed locks and streams.
- ClickHouse for large-scale data.
Performance
We conducted performance tests to measure ingestion and display latencies for Opik using 10,000 and 100,000 traces, each containing three spans, using our free and pro plans as a reference.
From these tests, we can conclude:
- Opik can ingest about 3,000 events per second in a local setup.
- Scaling from 40,000 events to 400,000 events (10x) did not degrade throughput (still ~3,000 events/sec).
- Ingested traces appear in the UI almost immediately (under 0.04 seconds).
These results are remarkable given the constraints of a simple local installation:
- Single replicas (no redundancy) for backend and frontend services.
- Containers with low resources allocated to ClickHouse, MySQL, and Redis.
- Docker limited to a maximum of 8 CPU cores and 18 GB total memory.
- The Opik Python SDK and the Opik platform sharing local machine resources.
Setup:
- The tests were performed on a MacBook Pro with an Apple M3 Pro CPU, 36 GB of memory, and Opik v1.4.5 running locally via Docker Compose:
- A single instance of the Python SDK (on the same machine) sent traces and spans to the Opik platform.
Metrics:
- Ingestion latency: Time taken for Opik to ingest all traces/spans.
- Dashboard display latency: Time until a trace becomes visible in the UI after ingestion.
Results:
1) 10,000 traces (30,000 spans, ~40,000 total events)
- Ingestion latency: 13.44 seconds (≈ 2,976 events/sec).
- Dashboard display latency: 0.03 seconds.
2) 100,000 traces (300,000 spans, ~400,000 total events)
- Ingestion latency: 2 minutes 8.84 seconds (≈ 3,104 events/sec).
- Dashboard display latency: 0.04 seconds.
Identifier Strategy
During Opik’s development, we needed an identifier strategy that favors scalability for data entities such as traces and experiments. We identified these requirements:
- Avoid leaking sensitive information externally (e.g., total record count).
- Balance the trade-off between possible metadata leakage (e.g., a timestamp) and performance gains.
- Extremely low probability of collisions.
- Independence from external coordination or configuration.
- K-sorted (to avoid index rebalancing and benefit from sorted data storage).
- Compact enough for economical disk usage (tables, indexes etc.) but large enough to accommodate high data ingestion rates.
- Multi-language support. Minimum: Java, Python, TypeScript/JavaScript.
We evaluated:
- ksuid.
- ulid.
- xid.
- UUID version 7.
After measuring, both in ClickHouse and MySQL:
- Generation speed.
- Insertion speed.
- Sort/retrieval speed
- Disk space usage (both tables and indexes)
We selected UUID v7 for most identifiers due to its performance, sortability, and standardization. For cases where exposing the creation timestamp might be problematic, we use UUID v4.
Backend
Opik’s backend uses Java 21 LTS and Dropwizard 4, structured as a RESTful web service offering public API endpoints for core functionality. Full API documentation is available here:
We rely on well-known open-source libraries to avoid reinventing the wheel:
- Lombok: to reduce Java boilerplate.
- Guice: for dependency injection.
- OpenTelemetry: for vendor-neutral observability.
- Reactive programming: using ClickHouse’s R2DBC client.
- Liquibase: for automated database migrations (ClickHouse and MySQL).
- MapStruct: to auto-generate Java object mappers.
- Spotless: for automated code formatting.
- PODAM: for autogenerated test data.
- TestContainers: for embedded ClickHouse, MySQL, and Redis in integration tests.
Frontend
Opik’s user interface is built with:
- TypeScript + React: for stateful, component-based UI development.
- Vite: as a fast and modern build system.
- Tailwind CSS: for utility-first styling.
- TanStack Router: for client-side routing.
- TanStack Query: for data synchronization and caching.
- TanStack Table: for robust table rendering and interactions.
- Zustand: for managing complex UI state.
The frontend is served by Nginx, which also functions as a reverse proxy. In the fully open-source version, Nginx does not enforce rate limits by default (though it can be configured to do so).
SDKs
Currently, Opik offers a Python SDK, and a TypeScript SDK will be released soon. Much of the boilerplate code for the SDKs is automatically generated from the OpenAPI specification using Fern. This approach helps us:
- Keep SDKs in sync with API changes (client and data models regenerating automatically).
- Simplify development and reduce manual coding errors.
The Python SDK uses a message queue and multiple workers, so it sends data to the Opik API asynchronously. This design ensures that latency or transient errors do not disrupt your LLM application.
ClickHouse
To meet Opik’s scalability requirements for high-volume data ingestion and fast queries, we compared:
- Apache Druid,
- ClickHouse,
- and StarRocks
against 22 different criteria (e.g., performance, scalability, operability, popularity, and licensing). After weighing these factors against Opik’s functional and non-functional requirements, we chose ClickHouse.
Opik uses ClickHouse for datasets that require near real-time ingestion and analytical queries, such as:
- LLM calls and traces
- Feedback scores
- Datasets and experiments
ClickHouse’s MergeTree engine family is vital for high ingest speeds and large data volumes. We use the ReplacingMergeTree engine variant to minimize costly data mutations (updates and deletes). Some highlights:
- Liquibase: manages schema definitions and versioning consistently.
- UUID v7: used for primary keys, leveraging natural timestamp ordering on disk to improve query performance.
- Primary key design: fields with lower cardinality appear first in the key to help with data partitioning and query efficiency.
- Deployment: Kubernetes Helm Charts for ClickHouse (alongside Zookeeper, the ClickHouse operator, and metrics exporters for Grafana/Prometheus).
The image below details the schema used by Opik in ClickHouse:

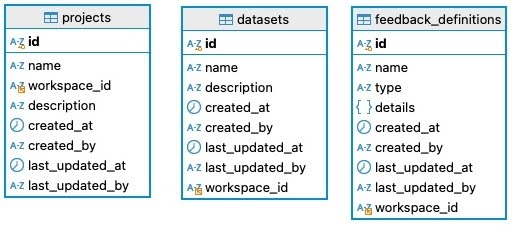
MySQL
MySQL provides ACID-compliant transactional storage for Opik’s lower-volume but critical data, such as:
- Feedback definitions
- Metadata containers e.g., projects that group related traces
- Configuration data
Again, Liquibase automates schema management and keeps MySQL definitions in sync with the rest of the platform.
The image below details the schema used by Opik in MySQL:
Redis
Redis is employed as:
- A distributed cache: for high-speed lookups.
- A distributed lock: for coordinating safe access to certain shared resources.
- A rate limiter: to enforce throughput limits and protect scalability.
- A streaming mechanism: Redis streams power Opik’s Online evaluation functionality; future iterations may integrate Kafka or similar platforms for even higher scalability.
Self Hosting
The easiest way to use Opik is via a free comet.com account. However, Opik’s full open-source version can also be self-hosted with all core features (tracing, evaluation, production monitoring), but without the integrated user management provided by comet.com.
There are two main ways to self-host:
- Local Installation
- Based on Docker and Docker Compose.
- Requires only Docker installed on your machine.
- Quick-start instructions:
- Kubernetes Installation
- Recommended for production-ready deployments.
- Highly configurable open-source Helm Charts (battle-tested at Comet).
More info:
Comet also provides scalable, managed deployment solutions if you prefer a hands-off approach.
Observability
Opik is built and runs on top of open-source infrastructure (MySQL, Redis, Kubernetes, and more), making it straightforward to integrate with popular observability stacks such as Grafana and Prometheus. Specifically:
- The backend uses OpenTelemetry for vendor-neutral instrumentation.
- ClickHouse deployments include an operator for real-time performance monitoring and metric exports to Grafana/Prometheus.
- Other components (MySQL, Redis, Kubernetes) also have well-documented strategies for monitoring.
Community Contributions
Opik’s roadmap and extensibility thrive on active community collaboration. We’re excited to see how users contribute by writing code, improving documentation, and sharing feature ideas. If you’d like to get involved, here are a few ways to get started:
- Submit feature requests and bug reports.
- Open Pull Requests to propose code or documentation changes.
Before contributing, please make sure to review our Contributor License Agreement and License. This ensures a smooth process and clarifies how your contributions are used and recognized. Together, we can make Opik an even more powerful platform for LLM observability.
Future Directions
Opik’s architecture is designed with extensibility in mind. Recent updates include a new Online evaluation feature that allows traces to be scored in real time, using an LLM as a judge. We plan to add user-defined Python code metrics soon, and a TypeScript/JavaScript SDK is also underway.
Some upcoming features will introduce notable architectural changes. For example, we plan to support file attachments like images or PDFs in new traces, which will require integrating an object storage system (e.g., Amazon S3 for AWS-based deployments or MinIO for self-hosting). You can explore more details on our public roadmap:
Conclusion
Opik is a significant step forward in LLM evaluation and observability, combining cutting-edge technologies with a carefully planned, modular architecture. Its open-source nature and free availability empower a growing community of users, while Comet’s infrastructure offers scaling options and commercial support if needed. Whether you adopt the managed service or self-host Opik, you gain a powerful, flexible framework for building next-generation LLM applications.
For more information, visit Opik’s GitHub repository and documentation.
Related Articles


