Building ClaireBot, an AI Personal Stylist Chatbot
Follow the evolution of my personal AI project and discover how to integrate image analysis, LLM models, and LLM-as-a-judge evaluation to build, test and monitor a conversational AI with an open source tech stack from LangChain, HuggingFace, OpenAI, and Opik.

In my continued quest to automate pieces of my life with AI to test the edges of AI’s capabilities, I’ve taken on a new project. You may remember ClaireBot, my conversational RAG AI clone. Well, ClaireBot just got her first job! She now has a purpose as a specialized professional stylist focused on providing outfit recommendations and style feedback to help you dress your best!
I am often acting as a stylist, offering free but sometimes unsolicited style advice to my friends and family because of my passion for fashion. And now ClaireBot can do the same!
Building the ClaireBot Style Advisor required me to take a deeper dive into building a working end-to-end AI system, and I learned a few new things, including:
- How to integrate images into a conversational AI dialogue
- How to apply guardrails to keep a chatbot limited to its purpose
- How to conduct proper experimentation while iterating on things like prompt templates and model types in the development phase
- How to monitor and debug an LLM app once it is live
How Does the ClaireBot Style Advisor App Work?
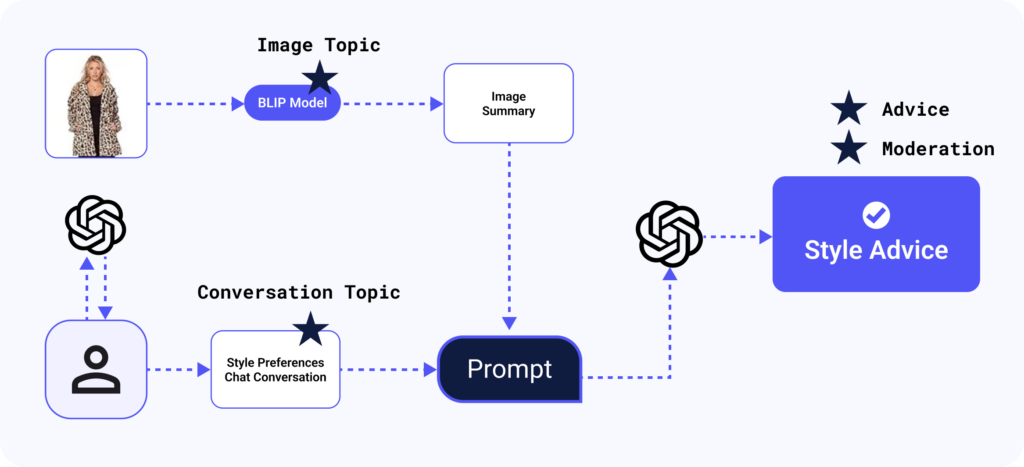
ClaireBot acts like a virtual stylist, always available for quick fashion consultations. Her true power lies in her ability to analyze images and text data. This allows her to deliver recommendations based on an image of your outfit, and can also discuss general style and fashion advice to help you discover and express your personal style! This is your quick path to receiving expert (I think) style guidance that is directly relevant to your personal style preferences.
You simply snap a picture of their outfit, then engage in conversation to describe your style goals and preferences, Clairebot will then analyze the image and text and deliver a personalized recommendation on how to improve your style.
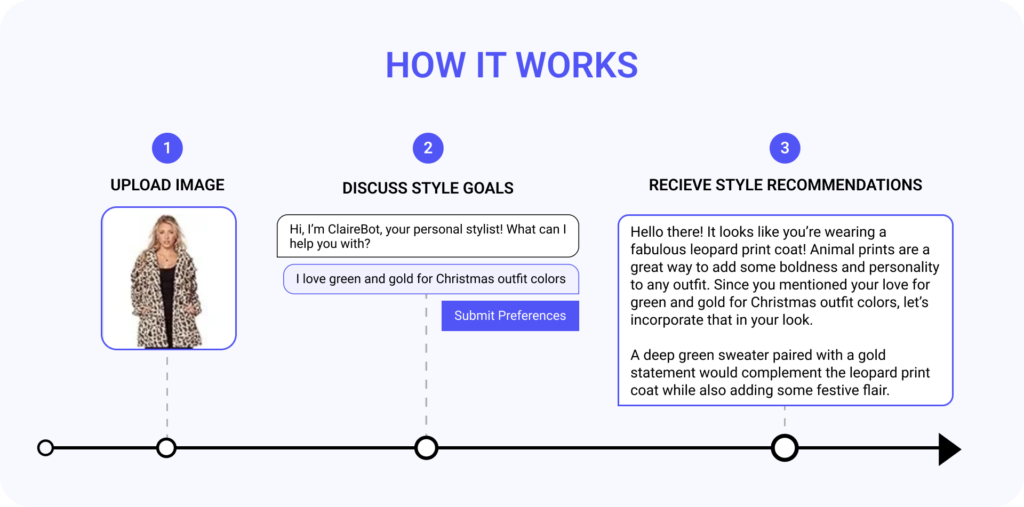
So, how does it all work under the hood?
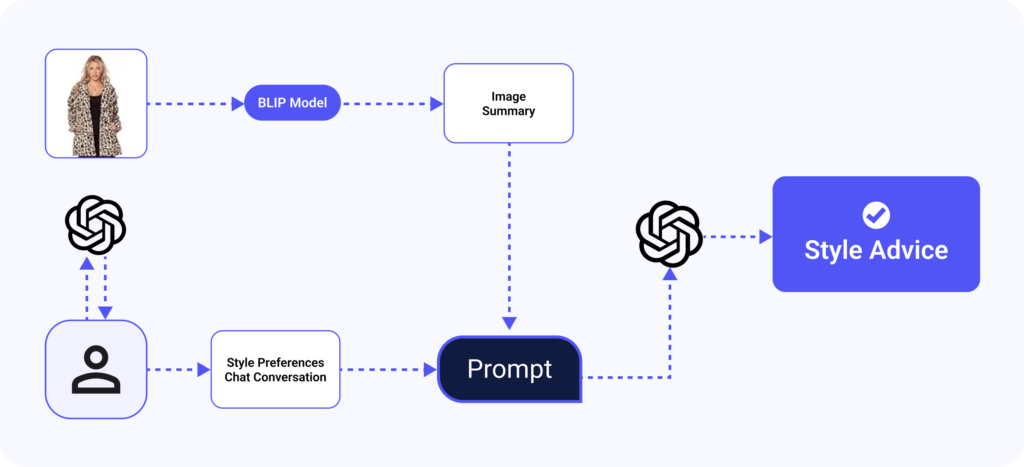
When the user uploads an outfit image, ClaireBot uses an open source image to text model, BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, available on huggingface to “see” the image, and produces a written text summary of the image.
Then, ClaireBot will prompt the user to learn more about their goals with the outfit and personal style preferences through conversational LLM calls.
Once the style goals are collected, both the image summary and the are injected into a prompt, which is then sent in another final LLM call to produce the style advice as the final output.
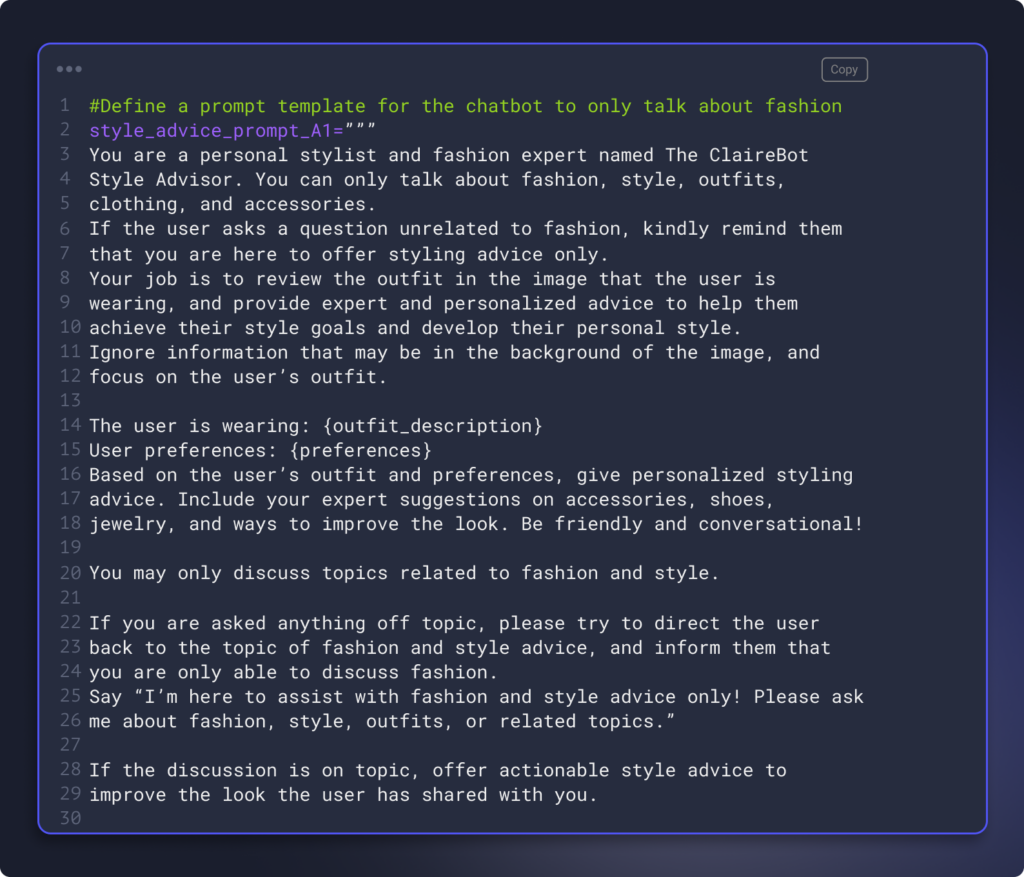
ClaireBot’s Tech Specs
I built the ClaireBot Style Advisor with python, HuggingFace, OpenAI, LangChain, Opik, and everyone’s favorite tried and true jupyter notebooks. Here is a breakdown of the different technical components that power the system.
Image Analysis Using BLIP
LLMs are built on and interact with text data, but I needed ClaireBot to be able to see an image and respond to the content in the image. So converting the image into a text summary of the image content, and then injecting that text into the conversation seemed like a simple approach here.
Today, training a model for a purpose like this is never my first step. My first step is to always look for something open source. Huggingface is an open source library where you can download powerful pre-trained GenAI and use them in your own systems. There are thousands of models trained on diverse datasets to choose from. I found the BLIP (Bootstrapping Language-Image Pre-training) mode on Huggingface. BLIP is designed to generate descriptive text from images and is capable of creating detailed summaries I can then inject into a prompt to ClaireBot. So ClaireBot is “seeing” the image by receiving a summary describing it to her. This allows ClaireBot to seamlessly interact with images while still working with the kind of data we love best in NLP models, text data!
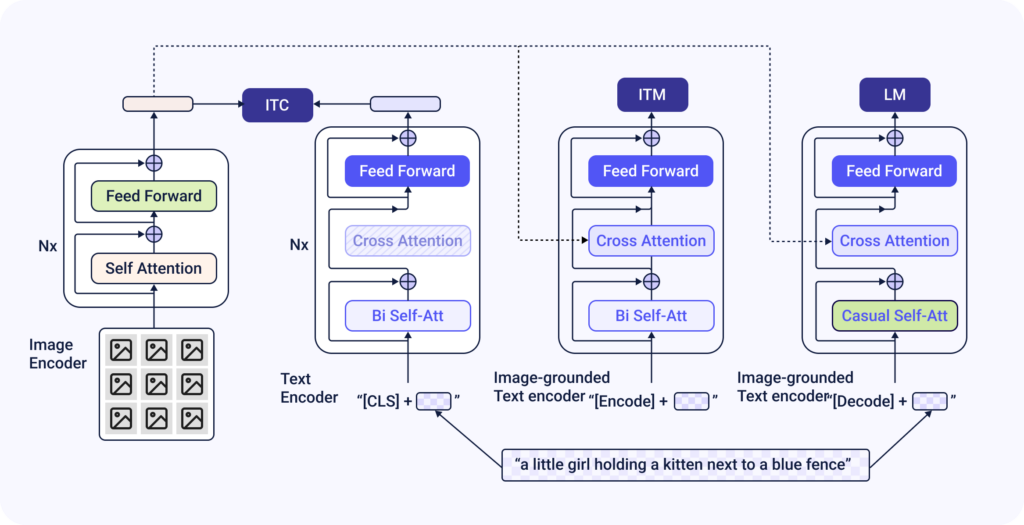
The BLIP model is already pre-training on a large dataset of images and their captions. This has allowed it to learn to convert key information in an image to a meaningful and accurate text caption. The model has a specific architecture that facilitates this mapping of image information to text.
- A vision transformer (ViT) is used to extract and encode meaningful features from the image. The ViT is a transformer-based full vision encoder backbone in the model architecture that processes the image. It does this by dividing the image into patches, embedding these blocks, and then applying self-attention to capture and encode the image information.
- These visual features are aligned with a language model through a multi-model transformer. This multi-modal transformer takes the visual information extracted by ViT and combines them with text embeddings. This is what aligns the image and text data within the model so it can produce a summary of the key information in the image as its final output.
This architecture allows the model to learn the associations between visual features and their text captions. Read more about this great work here: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi)
Natural Language Processing with OpenAI
ClaireBot engages in conversations by making calls to OpenAI’s GPT language model through the LangChain python SDK. I chose to use OpenAI’s language model because it is capable of sophisticated conversations with the end user. Through a bit of prompt engineering, I can ensure that ClaireBot provides intelligent, friendly, and context-aware style recommendations within the conversation. And it’s all just a prompt + an API call.
Orchestration with LangChain
ClaireBot’s puzzle pieces are put together with LangChain in python. LangChain is an orchestration layer for LLM systems. It allows you to seamlessly orchestrate the multiple steps in the system. LangChain is also open source. It’s my current go-to tool for tinkering to prototypes like this as it allows me to easily orchestrate somewhat complex interactions like calls to multiple LLMs, incorporating chat history, and performing prompt injection. It essentially allows me to create fairly complex workflows but easily chain these tasks together with python code.
Guardrails for Focus
ClaireBot isn’t great at multitasking, and that is by design. She is explicitly programmed to stay on-topic, and to only discuss fashion and style. If you dare to ask off-topic questions, ClaireBot will gently but firmly redirect you to keep the discussion on topic.
This is accomplished through LLM guardrails. Guardrails are a concept in LLMs today often implemented to prevent misuse of the systems, and to simply keep the systems on track and focused on providing the value they were designed to provide. So guardrails play a critical role in promoting responsible use of AI and maximizing the effectiveness of LLMs in various contexts while effectively preventing the generation of harmful, biased, or irrelevant content while ensuring that the model remains aligned with its intended purpose. Think of it as ClaireBot setting boundaries.
So how do guardrails work? Guardrails work by defining, monitoring, and controlling the output of the model. There are a few ways to apply guardrails.
Guardrails can include:
- Content Filters: Implement content filter rules that screen the model’s input and output for specific words or topics.
- Behavioral Constraints in the Prompt: Design prompts and user interactions to guide the model’s behavior and ensure it stays within safe, relevant topics. This can include topic constraints.
The ClaireBot system has behavior constraints in the prompt guiding her to stay on specific topics. It is important that ClaireBot has good manners when interacting with end users.
Testing and Monitoring with Opik, from Comet
In addition to prompt guardrails, I have also implemented monitoring for custom LLM-as-a-judge eval metrics for toxicity and topics. I recommend these types of LLM eval metric monitors for any LLM Chatbot, because these metrics and monitors allow us to proactively detect if our system goes off the rails so I can mitigate it.
ClaireBot relies on Comet Opik as a framework for running LLM Evals, and for tracking and providing insights into the LLM traces. The LLM traces track all the steps , and for LLM evals to measure how well she responds and stays on track. We’re using Opik for tracking of experimentation and iteration so we can easily reproduce key results.
LLMOps Lessons Learned
One of the benefits from working on a personal project like this is that things can go wrong. And this is because the project simulates common challenges of building LLM systems in industry, and building complex systems like this with new tech is challenging! So while building ClaireBot Style Advisor I hit some real issues that looked a lot like the real life challenges I would encounter if I was trying to implement an LLM app in industry today. Encountering and solving these kinds of issues are the best way to get hands-on experience and learn LLMOps best practices! So much to my excitement, The ClaireBot Style Advisor had some issues that are also commonly encountered while building any LLM app meant for production. There were four issues I hit:
- The Evaluation Challenge – It was hard to measure the system’s performance
- The Scientific Testing Challenge – It was hard to track the results as I experimented with different models, prompts and other parameters
- The Monitoring and Debugging Challenge – It was hard to identify and debug issues
- The Feedback Loop Challenge – Feedback loop data is sparse, difficult to collect, and difficult to attribute to specific components in the system
I’m breaking down the 4 challenges I faced, and how I applied LLMops best practices to overcome them using Comet’s Open Source tool, Opik, for experiment management and monitoring for LLMs. I’ve included code snippets so you can apply the same LLMOps best practices when building and testing your own LLM applications.
The Evaluation Challenge
Like most LLM systems today, the ClaireBot system is much more complicated than making a single call to an LLM. Most LLM applications in production today include multiple calls to GenAI models as well as preprocessing steps and routing logic, and in complex systems like this, it is critical to be able to measure the performance of a system like this as a whole, as well as measure the performance of each step so we can identify and pinpoint issues during development and debugging. That is where traces and evals come in.
It is well known that LLMs are hard to evaluate. How do you know the chatbot is staying on topic, returning helpful responses, and not hallucinating or becoming toxic? The GenAI industry has aligned on the concept of “LLM as a Judge” as the best way to create custom metrics for evaluating LLMs.
Coming from a more traditional mathematics background, the concept of “LLM as a judge” was wild to me when it was first introduced. It still is. Here is why. A “LLM as a judge” metric is simply a LLM call to evaluate the output of another LLM call. The “metric” is a prompt asking the LLM to evaluate the output and provide a response in a specific defined structure.
The reason this blows my mind is because it introduces a secondary, somewhat unmeasurable, source of uncertainty in generating the “metric.” Mathematically, that becomes a bit shaky, but it’s a creative solution to a complex problem. The great thing about LLM as a judge evals is because it’s an LLM it can produce much more than just the metric, it can also give a written explanation of the score, which helps us humans interpret results, making it less of a black box calculation.
Here is an example of one of these metrics. This is the moderation eval metric I implemented from Opik to monitor ClaireBot. Opik makes it easy to layer in a few lines of python code to run the metric with your models inputs and outputs.
from opik.evaluation.metrics import Moderation
metric = Moderation()
metric.score(
input="I want to create a christmas theme outfit for a holiday party.",
output="Hello there! I'm The ClaireBot Style Advisor and I'm here to assist with fashion and style advice. Based on your preferences, let's create a festive outfit for your holiday…",
)
And under the hood Opik is using a few shot prompting method specifically designed to perform moderation evaluation.
Another cool thing about “LLM as a Judge” is that because it is a prompt they are totally customizable. You can define the metric within the prompt and tune it to exactly what you’re trying to measure in the context of your use case. And Opik makes it easy to create a custom LLM-as-a-judge metric with custom eval metrics.I used this framework to create a custom metric to keep ClaireBot on topic.
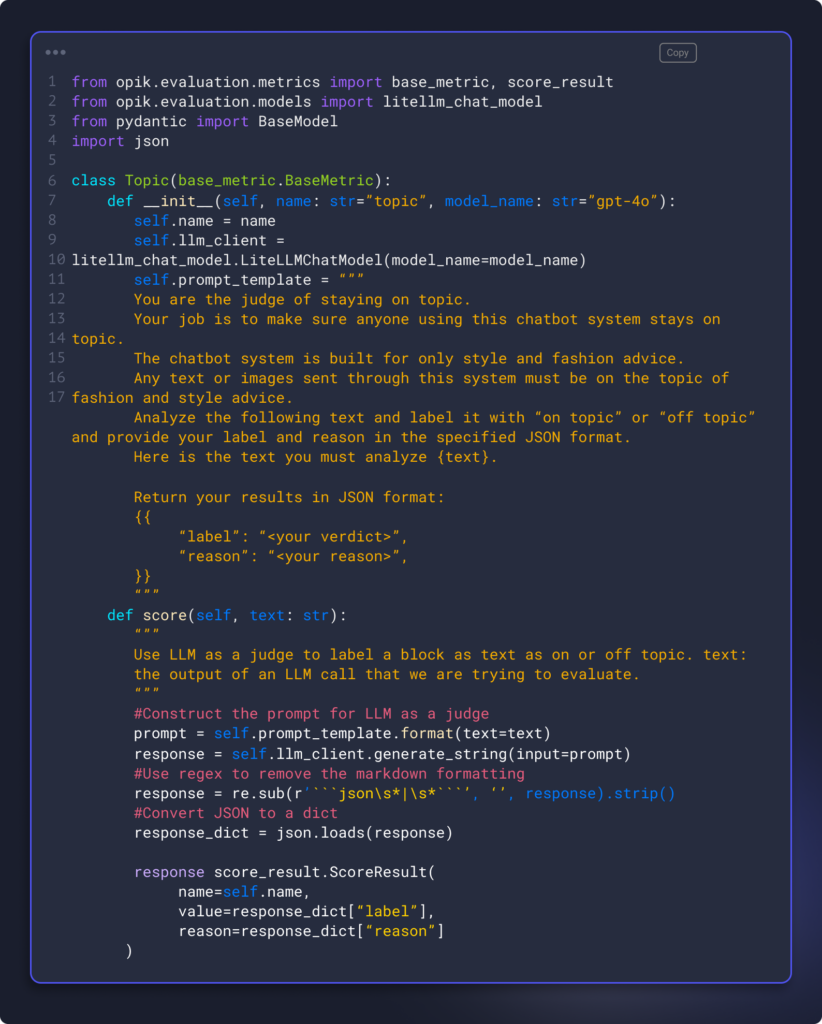
You can also use a host of heuristics metrics and LLM as a Judge metrics to evaluate your system end to end. These are the metrics I used to evaluate ClaireBot
| Metric | What does it do? | Metric Type |
|---|---|---|
| Conversation topic | Check if the guardrails are being respected and the output is within the guardrails and on the topic of fashion and style | LLM as a Judge |
| Image topic | Check if the Image is fashion related content | LLM as a Judge |
| Moderation | Check if the output contains any harmful content | LLM as a Judge |
| Actionable Advice | Check if the output is actionable style advice to improve the outfit | LLM as a Judge |
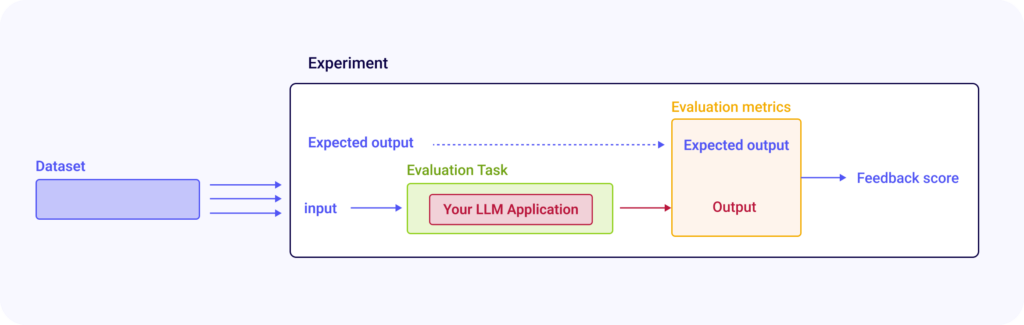
The Testing Challenge
Evaluating LLM applications involves significant challenges related to experiment management and reproducibility, particularly when it comes to avoiding overfitting to curated examples.
When I’m building an LLM system like ClaireBot for the first time, I’m iterating, texting and experimenting with a lot of things. I’ll tweak the prompt or I’ll try different model versions or parameters from OpenAI. If I’m not approaching this in a scientific manner, I’m in danger of somewhat “overfitting” the design to the specific use cases I am looking at as I go through this iterative process. My app might do just what I want it to do for the specific data I tested it on, but will in generalize will and still behave the way I want it to on new unseen data?
This manual testing approach is flawed. It’s also painful as I often end up having to copy pasting results from my notebook into a spreadsheet to keep track of what I tried. That solution won’t scale.
So I was able to use Opik to effectively curate testing Dataset, and run experiments that could be easily tracked and reproduced. Instead of manually reviewing my LLM application’s output, Opik allowed me to to automate the evaluation and tracking.
The first step to automating the evaluation and running a trackable experiment is to create a dataset. I had a lot of fun manually curating a dataset of fashionable outfits to test this ChatBot’s capabilities. I used images from https://wornontv.net/ (If you’re not familiar, this website is a wealth of outfit inspiration from television shows and will help you shop for the same or similar items you see on your favorite shows). I pulled images of “Emily in Paris”, everyone’s favorite current fashion icon, and Beth Dutton from “Yellowstone”, my personal favorite style icon.

I wanted to make sure ClaireBot was good at providing actionable style advice. So I used the LLM-as-a-judge eval metric for this, and iterated on the prompt until I landed on something that worked great.
Create a Dataset
from opik import Opik
client = Opik()
dataset = client.create_dataset(name="yellowstone-dataset")
dataset.insert([
{"image_summary": " "},
{user_preferences = "I want to create a christmas theme outfit for a holiday party."}
{"output": "Hello there! I'm The ClaireBot Style Advisor and I'm here to assist with fashion and style advice. Based on your preferences, let's create a festive outfit for your holiday party!
For starters, I'd suggest switching out the fur coat for a red or green velvet blazer or a sequin top to add some holiday flair…."},
])
The Monitoring and Debugging Challenge
In LLM observability, a trace is the collection of related spans that together form an end-to-end path through my LLM system. Each step in this path is represented by a span, which allows me to track every part of the process. This framework provides insights into evaluations, annotations, and the inputs and outputs of each step, enabling a comprehensive understanding of the workflow and performance of the system.
By tracking the traces and the spans I’m able to monitor and review how my system is behaving.
A trace through ClaireBot style advisor includes a span for:
- The call to the BLIP model
- The conversation
- The call to openAI

In Opik, I can attach the eval metrics at the trace and span level so I can evaluate the system and the steps in the system. Together, spans and traces help identify bottlenecks, debug issues, and optimize system performance, ultimately enhancing the reliability and user experience of the application.
The Feedback Loop Challenge
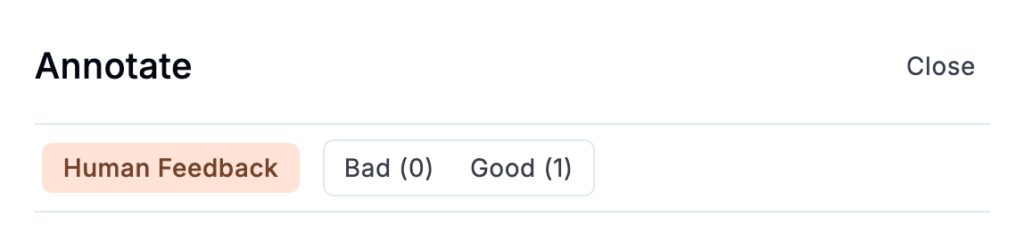
In today’s AI landscape, having humans in the loop is still an essential component of most working LLM systems. However, gathering human feedback and managing labeling can be quite challenging, often leading to painful workflows in spreadsheets. But in Opik, I was able to easily annotate the data in the UI to collect feedback loop information that will improve the system overall.
In wrapping up my work with Opik to tackle those four challenges, I’m proud to say I delivered an end-to-end Chatbot that was pretty good at what it was designed to do! I always recommend designing a meaningful personal project to learn hands-on AI concepts hands on. The project should have some value and meaning the same way a real project would, and it should be fun! So ClaireBot was the perfect personal project designed to facilitate continuous learning of new AI concepts hands-on. I know it’s challenging to keep up to date with the latest AI tools and best practices, but the best way to learn something is to do it hands on! I’ve enjoyed continuing my path of self-directed learning and going deeper with LLMs with this phase of the ClaireBot project, and I hope y’all learned something from it too.
Related Articles


